Zero Prompt Engineering - How to integrate AI in the OS
In light of Elon Musk's controversial claim about banning Apple devices if OpenAI is integrated into their OS, this post explores an innovative approach to AI integration through file system operations. By simplifying AI tasks like summarization and image generation into familiar file read/write ...

Recently, Elon Musk made a bold statement that if Apple integrates OpenAI into its operating system, his company will ban Apple devices. This is a very controversial statement, not only because of the freedom of choice, but also because it's not clear what he means by integration at the operating system level. Whatever this actually means, it is an appealing concept to provide AI capabilities to applications running on any OS, with little or no knowledge of the AI itself, but rather of the task to be performed, such as translation, image generation, etc.
In this post, we'll instead introduce the concept of abstracting AI at the file system level (don't worry, we're not developing drivers :) ). The goal is to provide a set of AI capabilities to applications (consumers) without any knowledge of the underlying LLM or prompt engineering. The abstraction is so simple that it's based on simple file system operations like read and write. In part one we'll introduce the concept of integrating LLM at the FS level, and in part two we'll implement a proof of concept.
So, let's dive in.
The File System Approach: Simplifying AI Integration
At its core, this approach treats AI interactions like file operations, a concept familiar to every programmer. To keep things simple, we'll introduce a file structure like this:
/llm/summarize/input
/llm/summarize/output
/llm/imagegeneration/input
/llm/imagegeneration/output
When any application with access to these folders writes a file in the input directory, it will be processed by the appropriate AI service. For summarization, the result will be written to the output directory in a folder with the same name as the input file (which is then removed from the input directory). This setup effectively creates a task backlog.
The service provider is responsible for determining the proper LLM to use (Claude, GPT, Mistral, etc.) based on the task at hand. This abstraction moves us towards a task-based approach, essentially providing a zero-prompt solution for the applications consuming this service.
Let's look at a concrete example:
Example: Document Summarization
Imagine you're building a content management system and want to add automatic summarization. With our file system approach:
- Your application saves a document as
article_12345.txtin/llm/summarize/input/. - The AI service detects the new file and processes it.
- A new folder
article_12345is created in/llm/summarize/output/containing the summary. - Your application can then read and display this summary alongside the original article.
The state transitions for this summarization process can be visualized as follows:
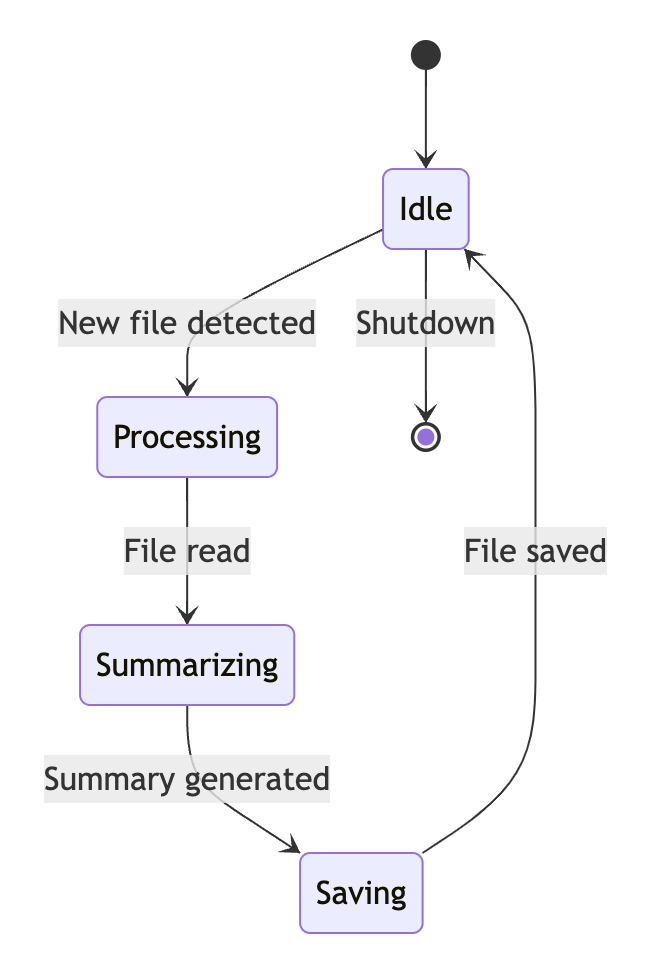
This state chart illustrates the key stages in the summarization process. The system starts in an Idle state, waiting for new files. When a file is detected, it moves to the Processing state. The Summarizing state represents the AI working on generating the summary. Once complete, the system enters the Saving state to write the output. Finally, it returns to Idle, ready for the next task.
Extending to Image Generation
We can easily extend this concept to other AI tasks. For image generation, we add another set of input/output folders:
/llm/imagegeneration/input
/llm/imagegeneration/output
Users can place a file with the description of the desired image in the input folder. The AI service will process this description and generate images, saving them in a corresponding folder in the output directory.
The Power of Abstraction
The whole concept revolves around abstracting the LLM idea itself and moving towards a task-based approach. This provides several key benefits:
- Simplicity: Applications don't need to understand the intricacies of different LLMs or APIs.
- Flexibility: The service provider can switch or upgrade LLMs without affecting the consuming applications.
- Scalability: The file system approach can easily handle batch processing and high loads.
- Language Agnostic: Any programming language that can perform file operations can use this system.
Challenges and Considerations
While this approach offers significant advantages, there are some challenges to consider:
- Performance: File I/O operations can be slower than direct API calls for high-frequency tasks.
- Security: Proper file permissions and encryption are crucial to protect sensitive data.
- Error Handling: Robust error detection and reporting mechanisms need to be implemented.
Conclusion
The file system-based approach to AI integration represents a novel way to bridge the gap between complex AI capabilities and everyday software development. By leveraging the universally understood concept of file operations, we open doors to AI integration for a broader range of developers and applications.
In the next part of this blog series, we'll dive into implementing a proof of concept for this system using Claude and GPT-4. Stay tuned to see how we bring this concept to life!