Why MCP Doesn’t Scale as You Might Think
You may have heard a lot about something called Model Context Protocol (MCP) in recent days and weeks, both in the news and here on Medium. This technology is becoming so widespread that it feels like almost every company with a digital product is getting worried about missing out and starting to introduce some kind of support for MCP.
If you remember the "early" days of AI, we were all fascinated by being able to chat with a PDF or chat with a YouTube video. With MCP, this concept has now evolved into chatting with almost anything: your database, your content management system (CMS), your file system, your email, and I imagine soon—if not already—it will include your car and your smart home.
Many people are calling it the USB-C of AI, and that's pretty much what it is.
Not All That Glitters Is Gold
Despite the incredible possibilities of accessing and combining data from everywhere – like checking your email every morning, doing research, drafting responses, then checking the news, and so on – there's one key consideration we might be overlooking (and perhaps don't want to talk about until problems arise):
putting AI applications into actual production use.
This is where the real "aha!" moment often happens: when you face critical cross-cutting concerns like security and scalability.
Why I'm Writing This Article
I've often discussed MCP and my fascination with the possibilities it brings. However, as a developer and architect, I have to think beyond the initial excitement. I believe it's crucial to consider security, maintainability, and the main focus of this article: scalability.
How MCP Works in a Nutshell
Before we dive into the scalability of MCP, let's briefly understand how it generally operates:
- Starting the Server: You begin by starting an MCP server (or your client application starts it for you).
- LLM Interaction: The MCP server then provides your Large Language Model (LLM) with an API-like interface. The MCP sends a request, and the LLM evaluates a response. The structure of this request-response interaction is determined at runtime – meaning when the LLM is already up and running. Unlike traditional APIs with pre-defined client stubs, the LLM doesn't know the API's structure beforehand. Instead, it asks the MCP server for the data structure and decides how to proceed based on that information and, of course, the user's requested task.
- Sending Requests and Evaluating Responses: The LLM sends its request and then evaluates the response. This process can loop if necessary, meaning it might call multiple tools from potentially different MCP servers.
- Crafting the Final Response: Finally, the LLM creates a response tailored to the user's original question, for example, "Summarize my mailbox and draft answers for urgent emails."
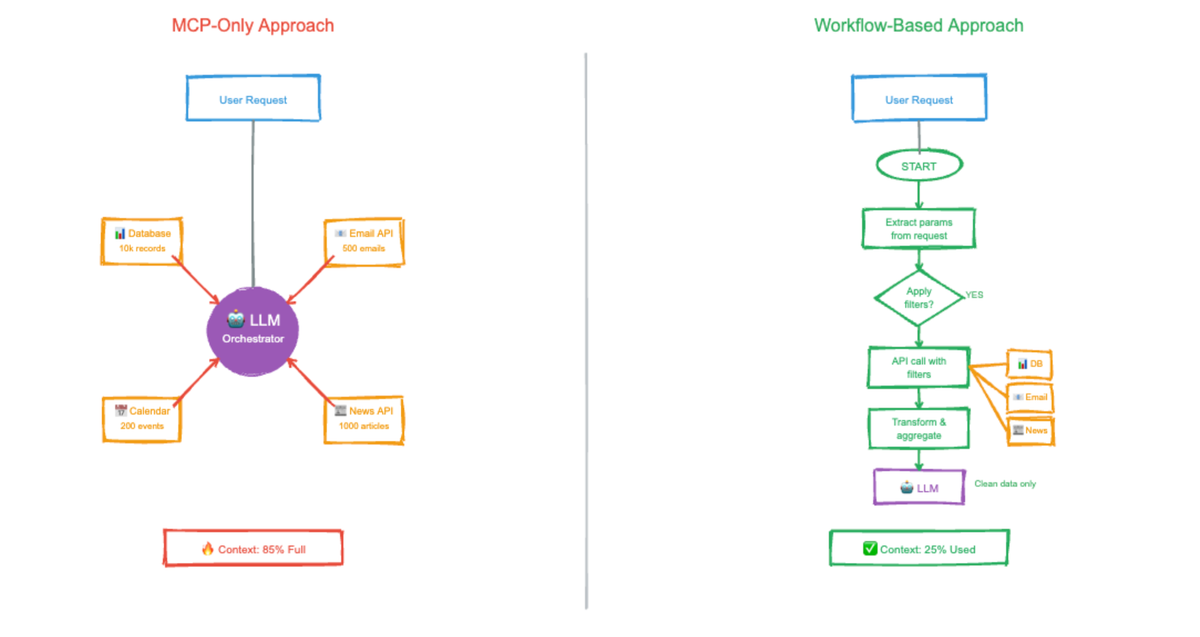
The Scaling Challenge
This all sounds quite simple and familiar, but if you look closer at steps 2 and 3, you might notice two things that significantly impact scalability: