Optimizing AI Agents API Calls in N8N: Building a Simple Caching Mechanism
Unlock the power of efficient workflows in N8N with a simple caching system! This blog post guides you through setting up a Code Tool node, designed to tackle rate limits of APIs and boost performance by storing and retrieving data seamlessly. Discover essential steps, implementation details, and...

In this post, we'll explore how to implement a simple but powerful caching system in N8N using a Code Tool node. This solution is particularly useful when working with rate-limited APIs or when you need to optimize workflow performance.
We'll begin by outlining the steps involved in setting up this caching system. Then, we'll dive into the details of each step, ensuring that you have all the necessary information and resources to implement it effectively.
Outline of Steps:
- Create an AI agent and attach the model and memory (optional).
- Create a new Code Tool node and enter the provided code.
- Add the tool description to inform the AI agent about its functionality.
- Add API calls to your model.
- Test the cache by adding and fetching entries.
The Problem
When building workflows in N8N, we often face scenarios where we:
Repeatedly make API calls to retrieve the same data, which can lead to hitting rate limits with external APIs. Additionally, there's a need to optimize workflow performance and save temporary data between workflow runs.
The Solution
We'll build a versatile caching system that can store and retrieve any data using a key, handle JSON objects, and provide cache management functions. This system will help in reducing unnecessary API calls, managing rate limits, and improving overall workflow efficiency.
Implementation
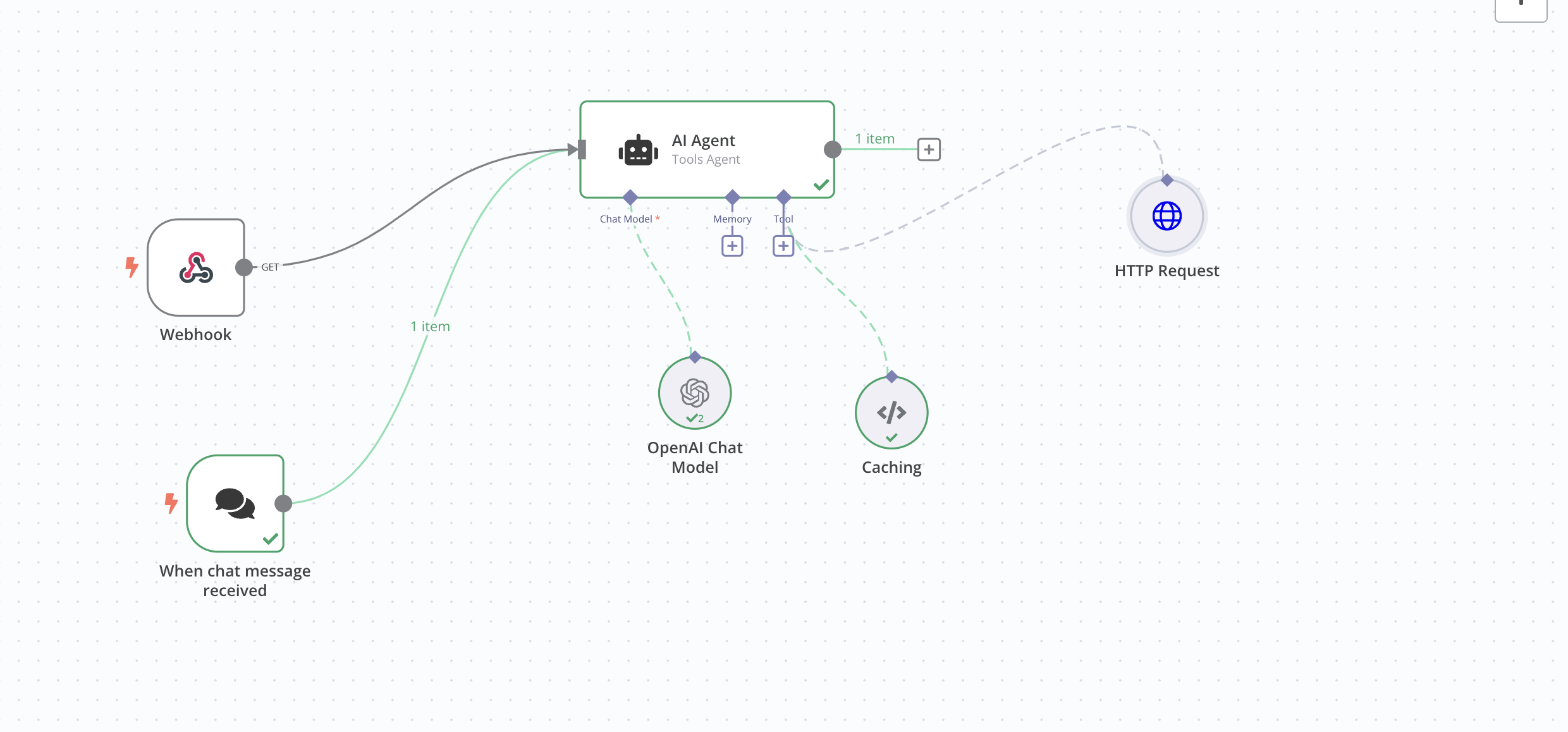
- Create an AI agent and attach the model and memory (optional)
- Create a new tool of type Code Tool and enter the code below
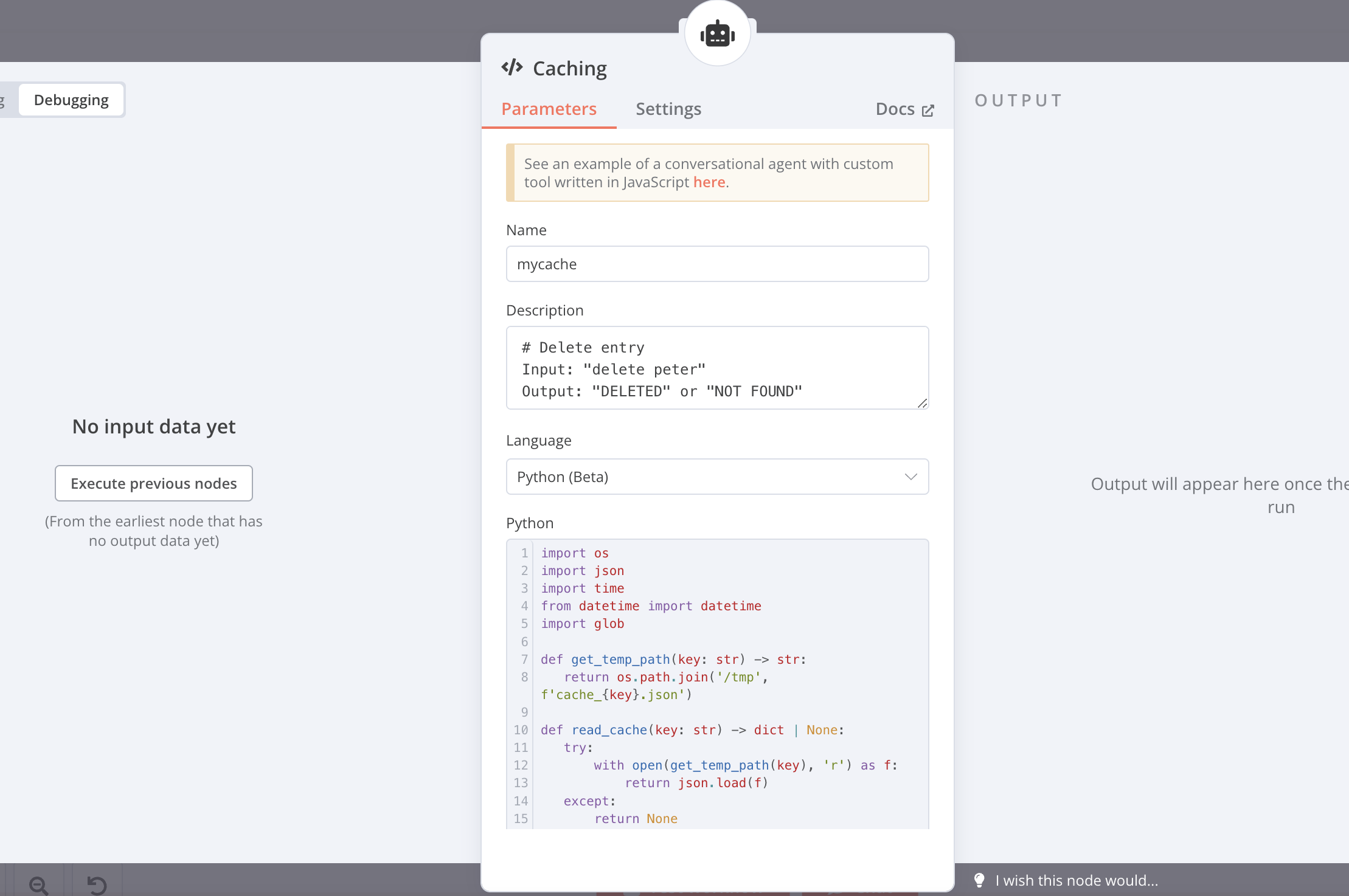
import os
import json
import time
from datetime import datetime
import glob
def get_temp_path(key: str) -> str:
return os.path.join('/tmp', f'cache_{key}.json')
def read_cache(key: str) -> dict | None:
try:
with open(get_temp_path(key), 'r') as f:
return json.load(f)
except:
return None
def write_cache(key: str, data: str) -> None:
with open(get_temp_path(key), 'w') as f:
json.dump({
'timestamp': time.time(),
'data': data
}, f)
def delete_cache(key: str) -> bool:
try:
os.remove(get_temp_path(key))
return True
except:
return False
def show_cache() -> str:
files = glob.glob('/tmp/cache_*.json')
output = []
for f in files:
with open(f) as cf:
data = json.load(cf)
key = os.path.basename(f).replace('cache_','').replace('.json','')
output.append(f"{key}: {data['data']}")
return "\n".join(output) if output else "No cache entries"
# Main execution
if not query:
return "ERROR: No key provided"
if query == "show":
return show_cache()
if query.startswith("delete "):
key = query.replace("delete ", "", 1)
return "DELETED" if delete_cache(key) else "NOT FOUND"
try:
# Try parse as JSON
data = json.loads(query)
if isinstance(data, dict):
for key, value in data.items():
write_cache(key, value)
return f"STORED: Cache entry for key '{key}' with value '{value}'"
except:
# Not JSON, treat as normal key
cached = read_cache(query)
if cached:
return f"CACHED: {cached['data']}"
else:
write_cache(query, f"Generated content for {query}")
return f"NEW: Generated content for {query}"
In the tool description, add the following text so the AI agent knows what it does and how to call it:
# Store JSON
Input: '{"Key": "Value as JSON"}'
Output: "STORED: Cache entry for key with value "
# Get value
Input: "Key"
Output: "CACHED: Cached Value"
# Show all
Input: "show"
Output: "Key: value1\nvalue2: other_value"
# Delete entry
Input: "delete peter"
Output: "DELETED" or "NOT FOUND"
That's it.
Now you can add any API calls to your model like this.
To ensure the cache works correctly, instruct the model in the chat to use caching.
Let's put some test entries in the cache.
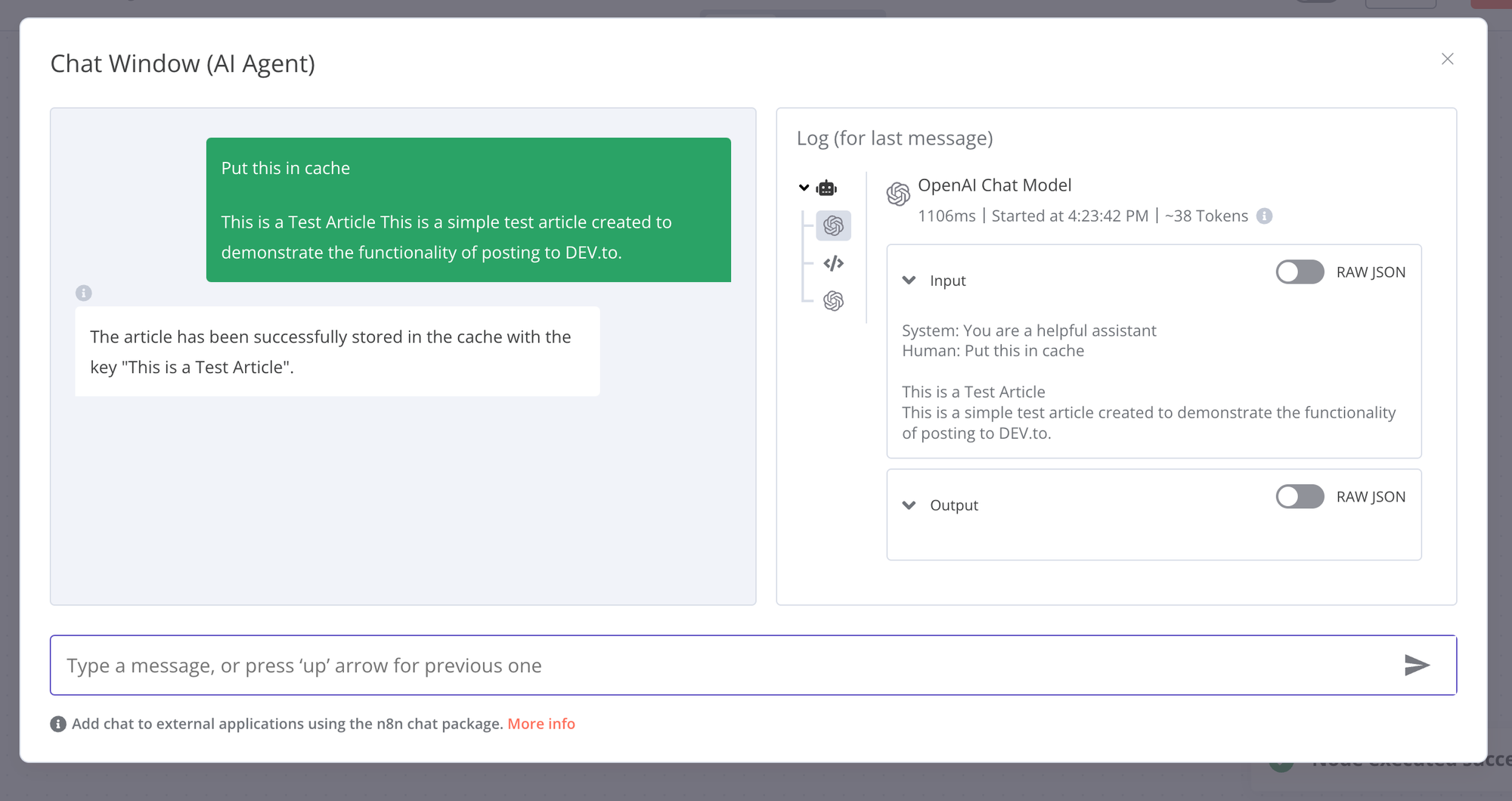
And fetch them.
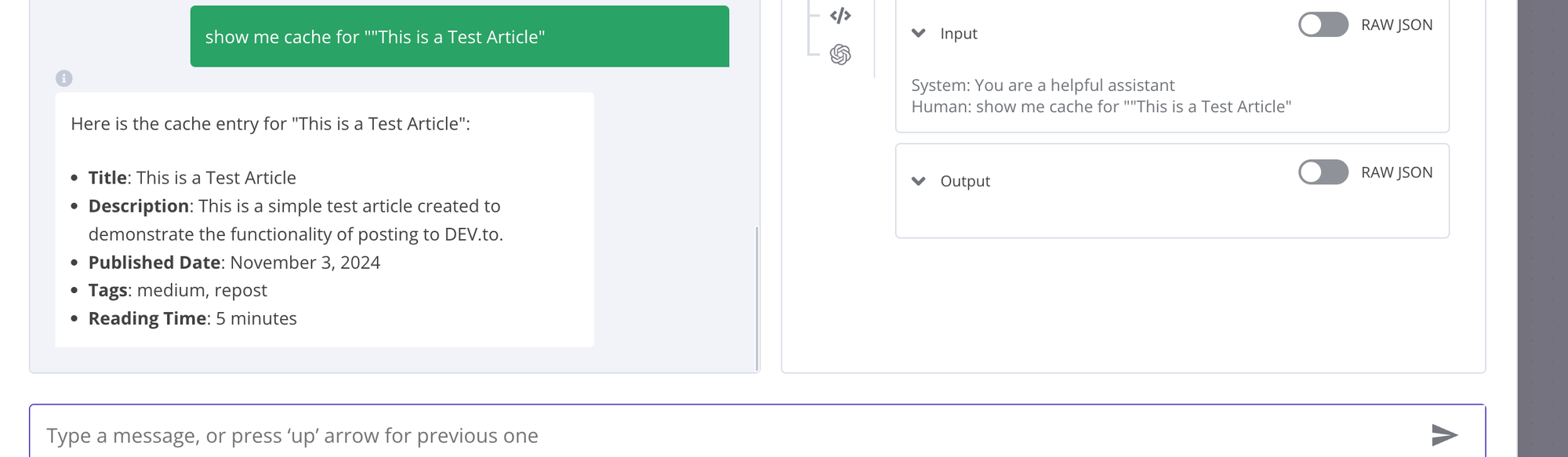
That's it. Now you can use this approach to enrich your API-based workflows.
Conclusion
This simple caching system can significantly improve your N8N workflows by reducing API calls, improving response times, managing rate limits, and providing temporary storage. Remember to adjust the cache duration and storage method based on your specific needs. For production environments, you might want to consider using Redis or a database for more robust caching.
Next Steps
Add cache compression for large datasets, implement cache versioning, add batch operations, and consider distributed caching for multi-node setups. Feel free to modify and expand upon this implementation for your specific use cases!



