The Hidden Costs of Sticking to OpenAI (and What to Do Instead)
Explore the rapid growth of LLM models beyond OpenAI in this insightful blog post. Discover the importance of speed, cost, and performance when selecting a provider. Real-world examples demonstrate how alternatives like Together and Fireworks can yield impressive improvements in response times. O...

In the beginning, there was OpenAI… then came the flood. :)
Over the past two years, the number of LLM models has grown significantly, each with its own pros and cons. Yet, many companies still rely heavily on OpenAI, possibly due to convenience or a lack of understanding of alternatives.
In some cases, OpenAI might be a good choice. However, in many of the use cases I’ve observed, it might not be ideal—especially if speed is crucial to your application. Speed here refers to the response time, usually measured in tokens per second.
Disclaimer: I am not recommending any specific provider or model in this post. Instead, I want to illustrate how comparing models can make a significant difference when you care about quality, price, and speed. Especially when going into production, these factors really matter.
---
Comparing Models and Providers
Before considering any alternatives, it’s essential to:
- Look at leaderboards and benchmark metrics for the models themselves.
- Compare performance across different providers.
Even the same model can behave differently depending on the provider. For example, a Llama model on Fireworks may have drastically different response times compared to the same model on Together.
Benchmark Example:
https://artificialanalysis.ai/models/llama-3-2-instruct-1b/providers
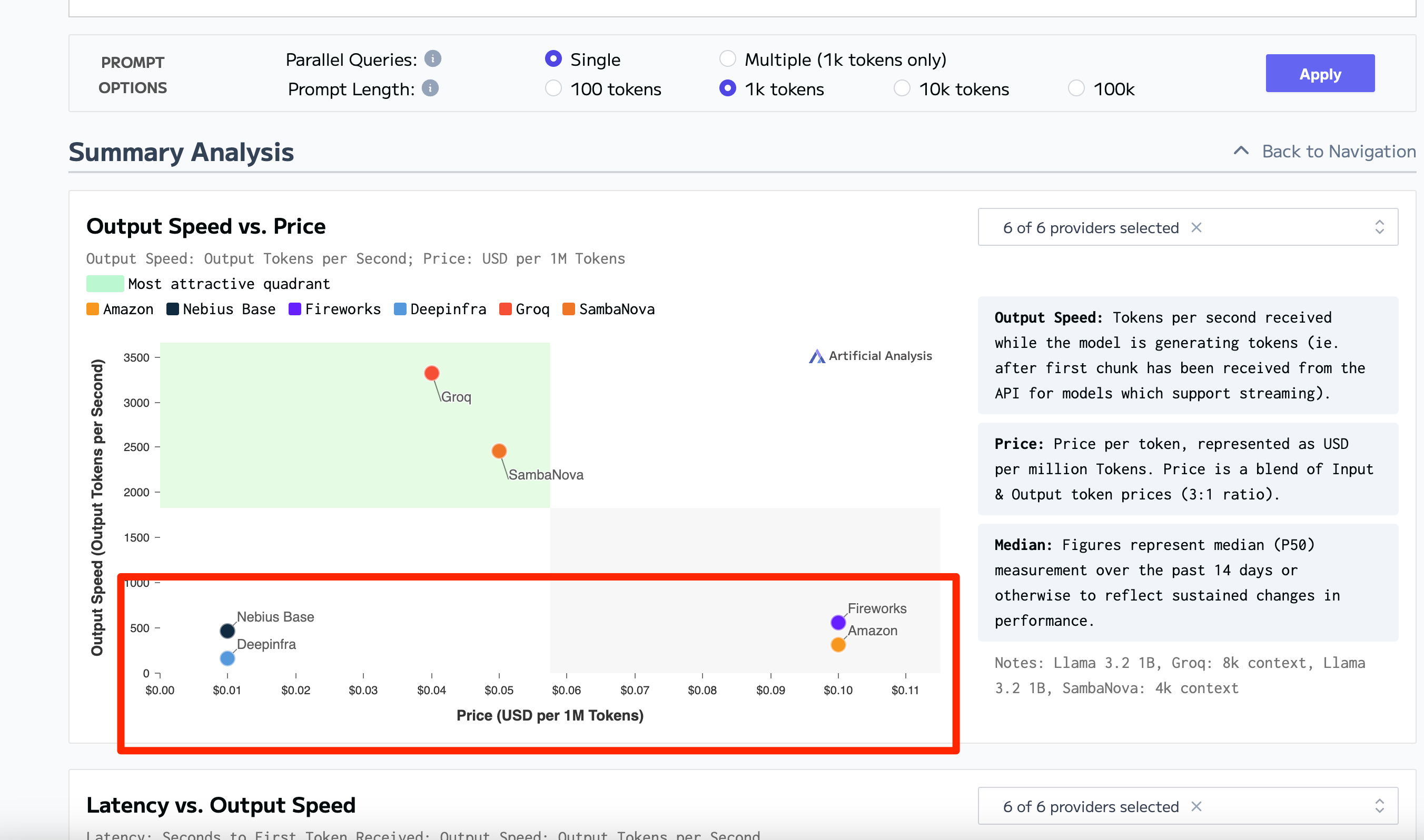
---
Concrete Example: Summarizing API
Below is a real-world scenario. We built a summarizing API (it does a bit more than just summarizing, but that’s not crucial here). The key metric is the speed-to-cost ratio. Initially, we used OpenAI as the provider.
When provider = openai is selected, it automatically chooses gpt-4o-mini, the fastest OpenAI model (with Azure possibly being slightly faster).
Running a summary on one of my blog posts took about 4.5 seconds:
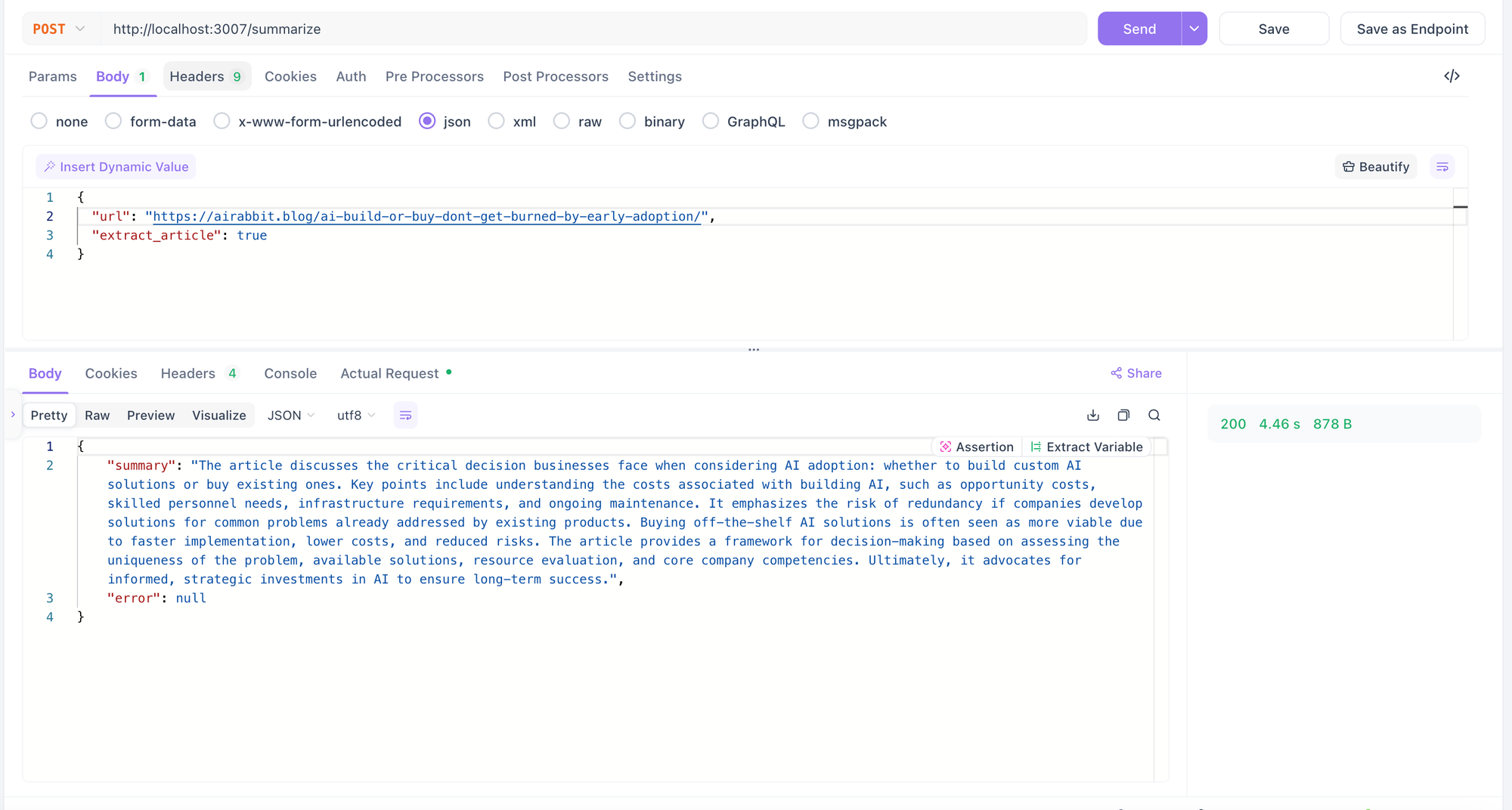
---
Switching Providers: Llama on Together.ai
Next, we switched to Llama 3.1 8b on Together.ai. The difference was significant, despite generating more output tokens.
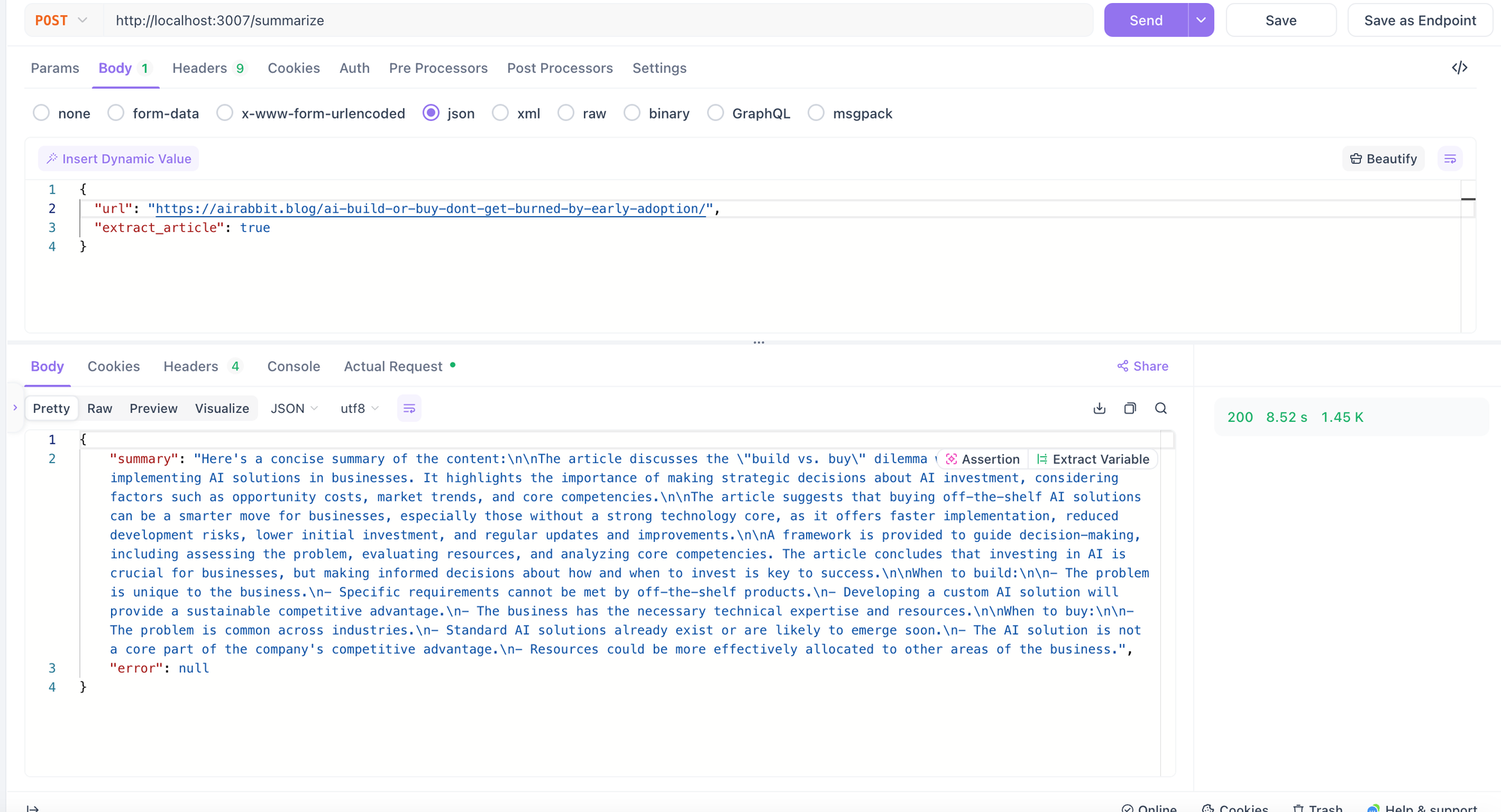
After multiple tests, the speed difference remained huge—almost a 3x improvement compared to OpenAI. And not just Together, but Fireworks.ai also showed similar improvements.
Note: Different models on the same provider can yield different results. On Together, the 8b model performed at 240–270 tokens/second, more than double gpt-4o-mini.
---
Cost Considerations
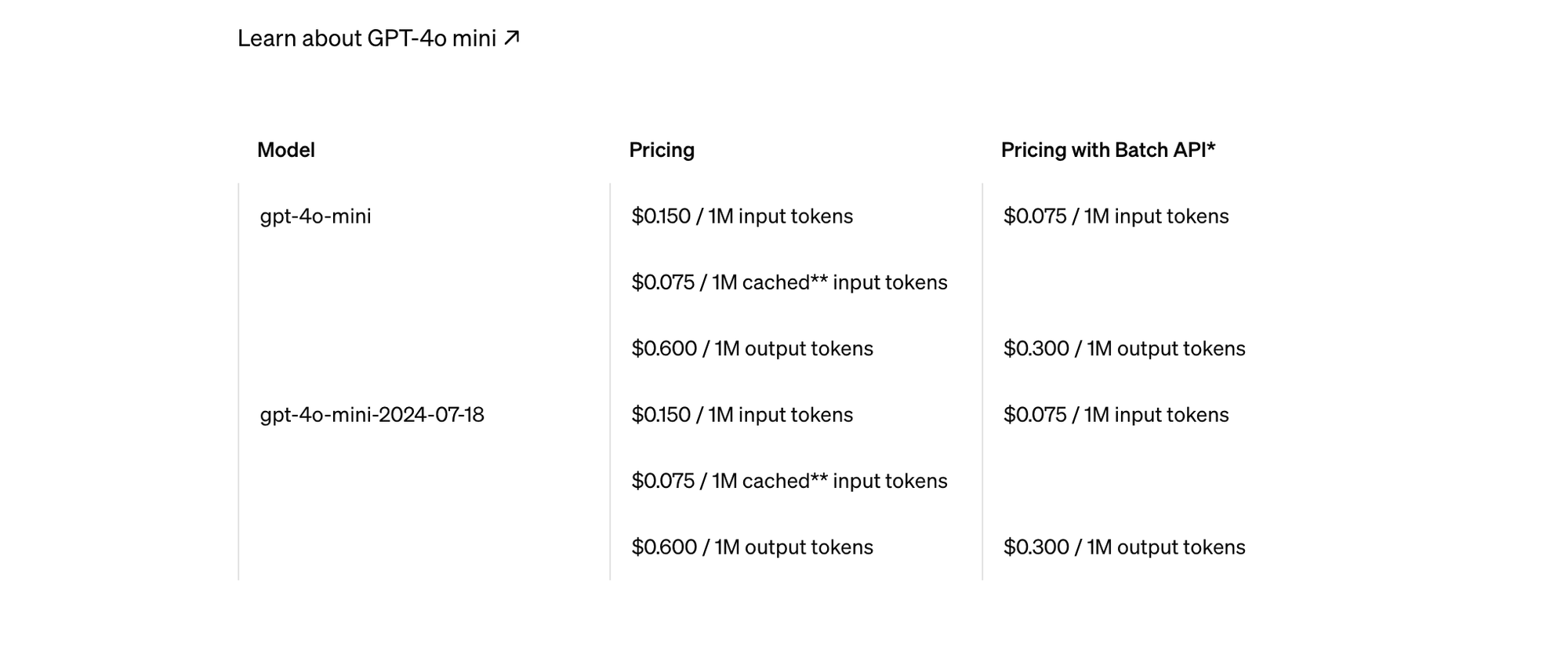
OpenAI Pricing
OpenAI charges $0.15 per million input tokens and $0.075 per million output tokens:
https://openai.com/api/pricing/
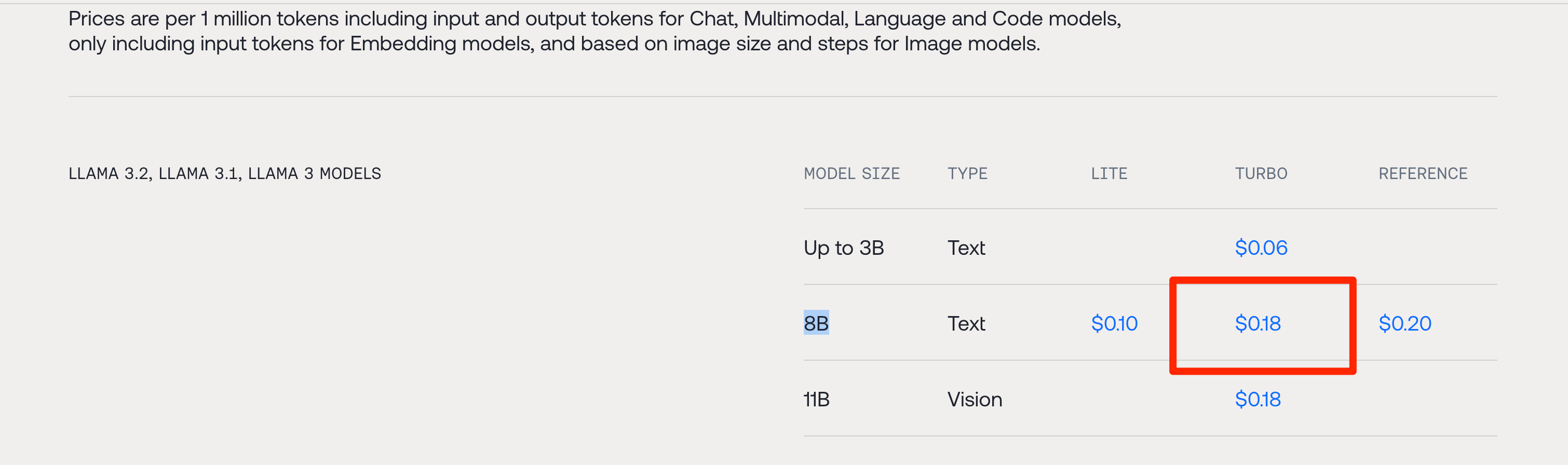
Together Pricing
Together’s pricing is around $0.20 per million tokens.
https://www.together.ai/pricing
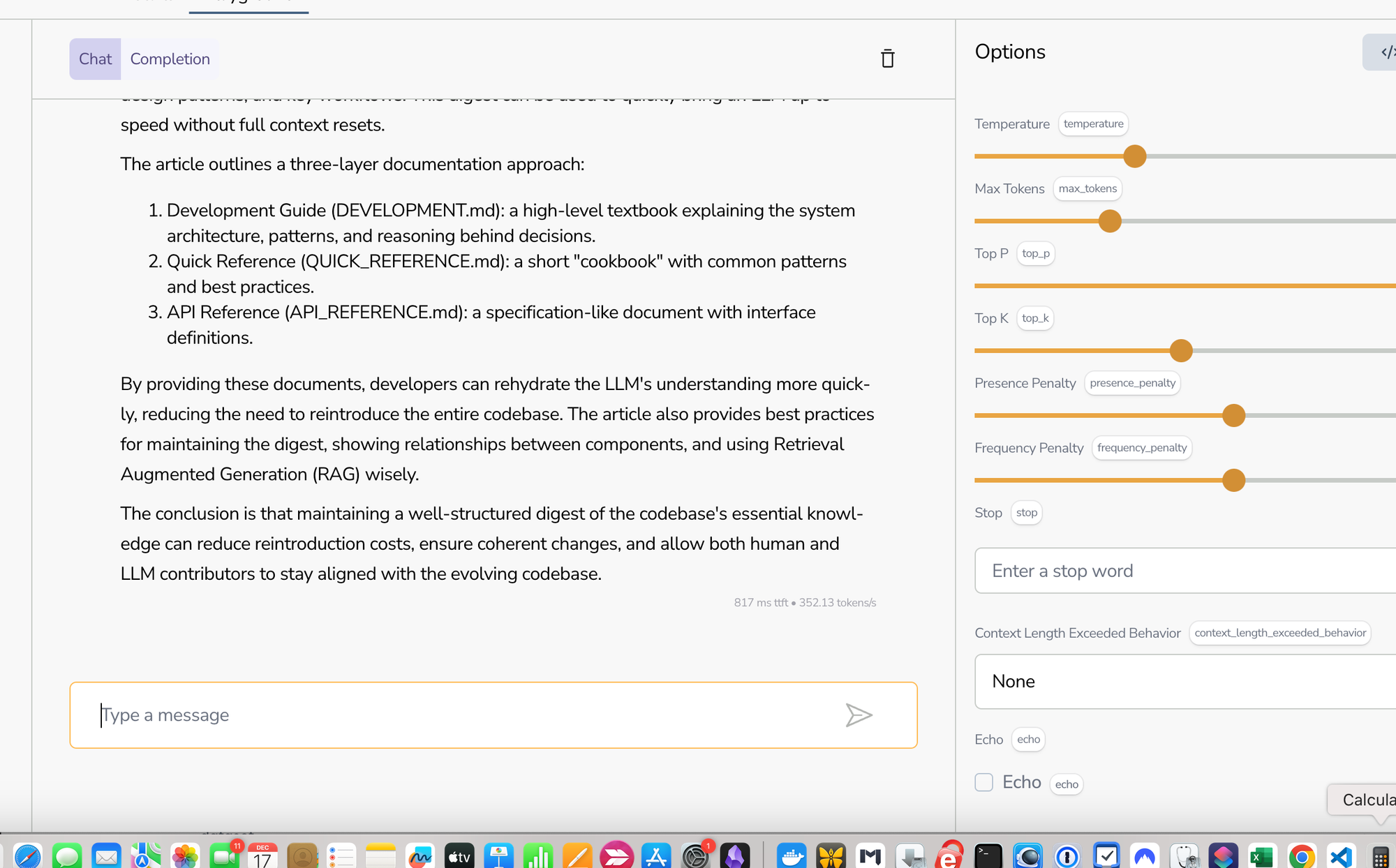
Fireworks Performance and Pricing
On Fireworks.ai, we tested the same scenario:
https://fireworks.ai/models/fireworks/llama-v3p2-3b-instruct/playground
The response time was even faster—about 350 tokens/second.
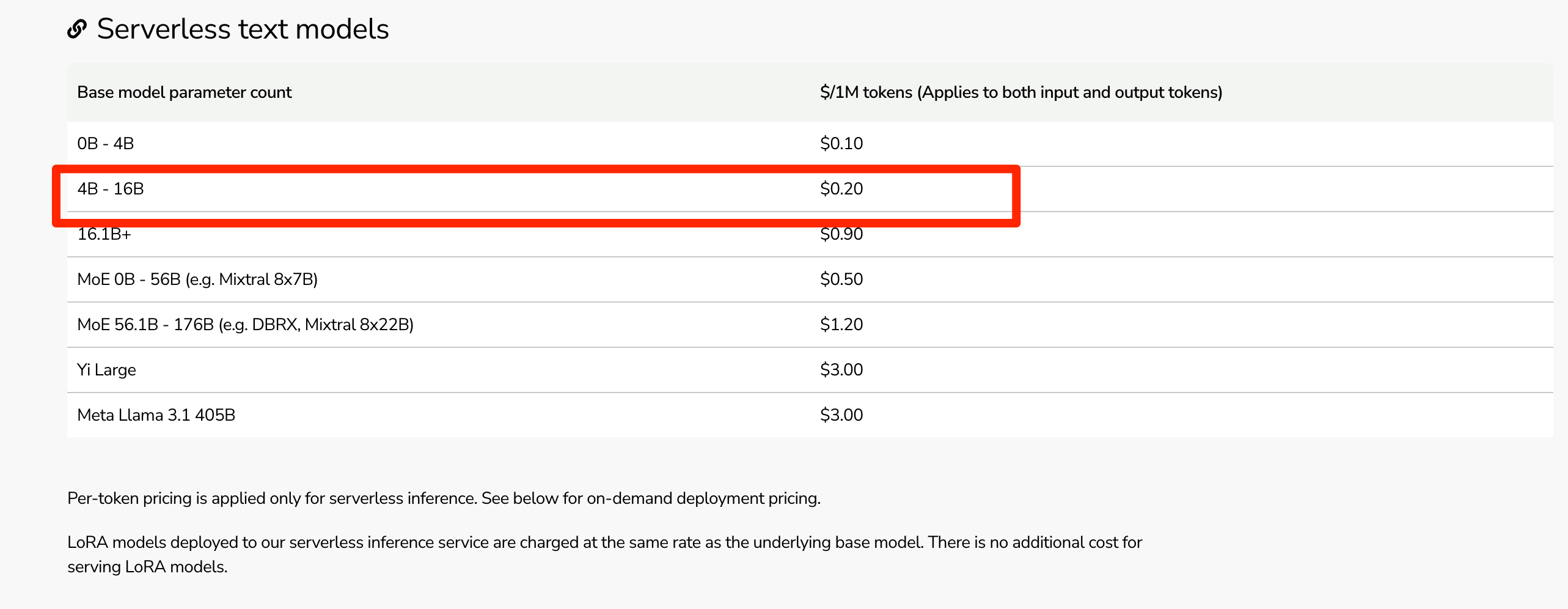
The pricing is $0.20 per million tokens, the same as Together:
---
Wrap-Up
In this blog post, we explored alternatives to OpenAI, focusing particularly on pricing and speed. Quality, toxicity, and other factors also matter, but once you confirm the feasibility of your application, it’s worth looking at benchmarks and optimizing your setup to save costs and improve performance.
---
Useful Links
Benchmarks:
https://artificialanalysis.ai/models/llama-3-2-instruct-1b/providers
Together Models:
https://api.together.ai/models
Together Playground:
https://api.together.ai/playground/chat/meta-llama/Llama-3.3-70B-Instruct-Turbo
Fireworks Playground:
https://fireworks.ai/models/fireworks/llama-v3p2-3b-instruct/playground
Fireworks Models:
https://fireworks.ai/models
OpenAI Pricing:
https://openai.com/api/pricing/



