The AI That Never Forgets: Understanding Infinite Conversations in Cline and other Chatbots
AI models often face the "context window limit," leading to disjointed conversations. Cline, an AI code assistant, tackles this by using advanced context management, ensuring comprehensive conversation tracking and intelligent truncation strategies. It preserves key system and custom instructions...

Have you ever had a long conversation with an AI model like Claude, only to find it suddenly "forgets" crucial details from earlier in the chat? This common frustration stems from a fundamental challenge in AI: the "context window limit." This limit defines the maximum amount of information (or tokens) an AI can process at any given moment. When a conversation exceeds this boundary, the AI can lose track of previous turns, leading to disjointed responses and a degraded user experience. Cline, an AI code assistant, directly tackles this problem with a sophisticated context management and truncation system designed to keep conversations coherent and prevent memory loss, even during the most extensive interactions.
This blog post will delve into the intelligent mechanisms Cline employs to gracefully handle instances where the token context length limit is exceeded, effectively preventing AI models from "forgetting." We'll explore its detection, adaptive truncation strategies, proactive optimization techniques, robust error handling, and crucial preservation of system and custom instructions, all ensuring a consistently productive and intuitive interaction where context is king.
Understanding the Context Window Challenge
Large Language Models (LLMs) operate with a finite capacity for understanding and generating text, defined by their "context window." This window represents the maximum number of tokens (words, sub-words, or characters) that the model can consider at once. As a conversation progresses, the history of messages consumes more and more of this context. If the conversation becomes too long, the system risks losing earlier, critical information, leading to the AI producing irrelevant or nonsensical responses. Cline's architecture is built to preemptively and reactively manage this, ensuring the AI always has the most relevant context at its disposal.
1. Detection and Automatic Handling
Cline's system proactively monitors token usage, preventing abrupt conversation breaks. It continuously tracks the total tokens consumed by previous API requests, encompassing input, output, and even cache reads/writes. This vigilant monitoring allows the system to anticipate when it's approaching the model's maxAllowedSize context window limit. Once this threshold is met or exceeded, Cline's intelligent truncation logic is automatically triggered, acting as a crucial safety net to maintain conversational integrity.
The system leverages real-time token tracking to make informed decisions. This is not just about counting words; it's about understanding the computational load of the conversation. By parsing ClineApiReqInfo from previous responses, Cline can precisely calculate totalTokens = (tokensIn || 0) + (tokensOut || 0) + (cacheWrites || 0) + (cacheReads || 0). This comprehensive calculation provides the most reliable indicator for when the context window is on the verge of being overran. The system's ability to automatically initiate truncation based on this precise data ensures that users rarely encounter explicit "context window exceeded" errors, making the process almost invisible to them. This proactive detection ensures conversations continue seamlessly.

Figure 1: Cline's system vigilantly monitors token usage (input, output, cache data) against the maximum allowed size, dynamically detecting when the context window is approaching its limit to trigger automatic handling.
2. Intelligent Truncation Strategy
When Cline determines that truncation is necessary, it doesn't just randomly cut off parts of the conversation. Instead, it employs an intelligent and adaptive truncation strategy designed to preserve the most critical elements of the dialogue. This strategy is adaptive, meaning the amount of conversation history removed depends on the severity of the context overflow. If the totalTokens/2 is already greater than the maxAllowedSize for the current model, a more aggressive "quarter" strategy is applied, removing 3/4 of the conversation history. Otherwise, a "half" strategy is used, removing 1/2 of the conversation.
Crucially, Cline prioritizes structural preservation. The system always retains the very first message of the conversation, which typically contains the user's original task or system instructions. This ensures that the core objective of the interaction is never lost. Furthermore, it meticulously maintains the user-assistant conversation structure, ensuring that the last message removed is a user message, thus keeping the conversation flow logical and coherent (e.g., maintaining user-assistant-user-assistant patterns). This meticulous approach guarantees that even after truncation, the conversation remains intelligible and aligned with the user's intent, minimizing disruption and the need for repetitive input. This intelligent strategy ensures relevant context is always available.

Figure 2: Cline's adaptive truncation strategy selectively removes conversation history (half or quarter) while always preserving the original task and recent user-assistant messages to maintain dialogue flow.
3. Context Optimization Before Truncation
Before resorting to any form of truncation, Cline takes a proactive step: context optimization. This crucial phase is designed to squeeze as much valuable context as possible into the available window, potentially avoiding truncation altogether. The system analyzes the conversation history for elements that can be optimized, such as redundant information or large blocks of text that might be condensed without significant loss of meaning. This could involve, for example, identifying and summarizing lengthy tool outputs or filtering out less critical details from file reads.
The effectiveness of these optimizations is rigorously measured. If the context optimizations manage to save 30% or more of the characters that would otherwise consume the context window, the system intelligently determines that truncation is unnecessary. This threshold-based decision-making is a testament to Cline's commitment to preserving conversational depth and continuity. It's a "first line of defense" that ensures the conversation remains as complete as possible, enhancing the user experience by reducing the instances of information loss or conversational jumps that truncation might otherwise introduce. This step is vital for dynamic and complex interactions where every piece of information might hold significance. Context optimization is Cline's first line of defense.
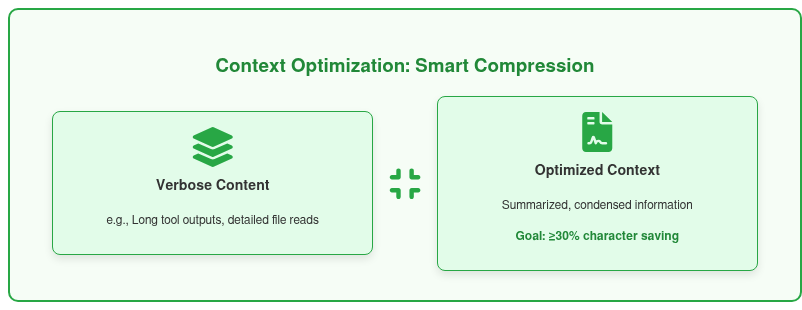
Figure 3: Cline actively optimizes verbose content (e.g., large code blocks) into condensed summaries. If this saves ≥30% characters, truncation is proactively avoided.
4. Robust Error Handling for Context Window Exceeded
Despite the intelligent detection and optimization mechanisms, there might be edge cases or sudden changes in model context window sizes (e.g., switching from a 200k token model to a 64k token model) that lead to an API request failing due to a context window error. Cline is equipped with specific, robust error detection and retry logic to handle these scenarios gracefully. It specifically checks for context length errors from different API providers, such as OpenRouter (checking for error code 400 and context length in the message) and Anthropic (checking for invalid_request_error and prompt is too long in the response).
When such an error is detected, the system immediately applies an aggressive truncation strategy, forcing a "quarter" truncation to free up substantial space. It then automatically retries the API request once. This immediate retry mechanism often resolves the issue without user intervention. If the request still fails after the automatic retry, and the conversation has more than three messages (meaning there's still enough history to potentially truncate further), Cline presents a user-friendly retry option, empowering the user to continue the conversation. However, if the conversation is too short to truncate further (e.g., three messages or less), the conversation might become "bricked," indicating that the system cannot proceed without manual user intervention or starting a new task, a rare but necessary fallback. Cline's error handling ensures resilience and user control.



