Stop building RAG pipelines like it’s 2023
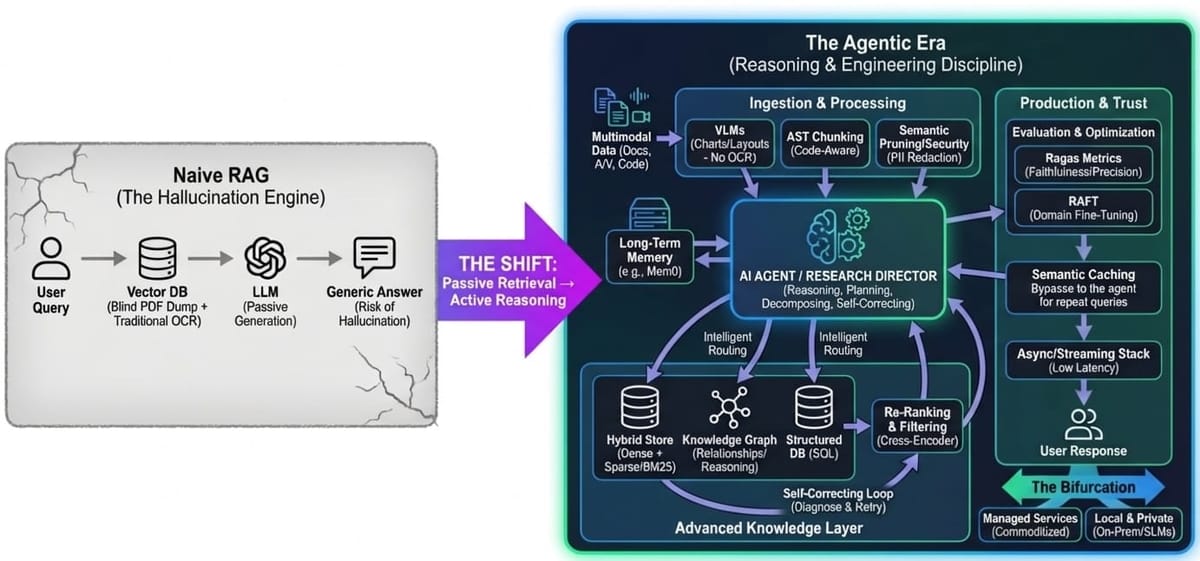
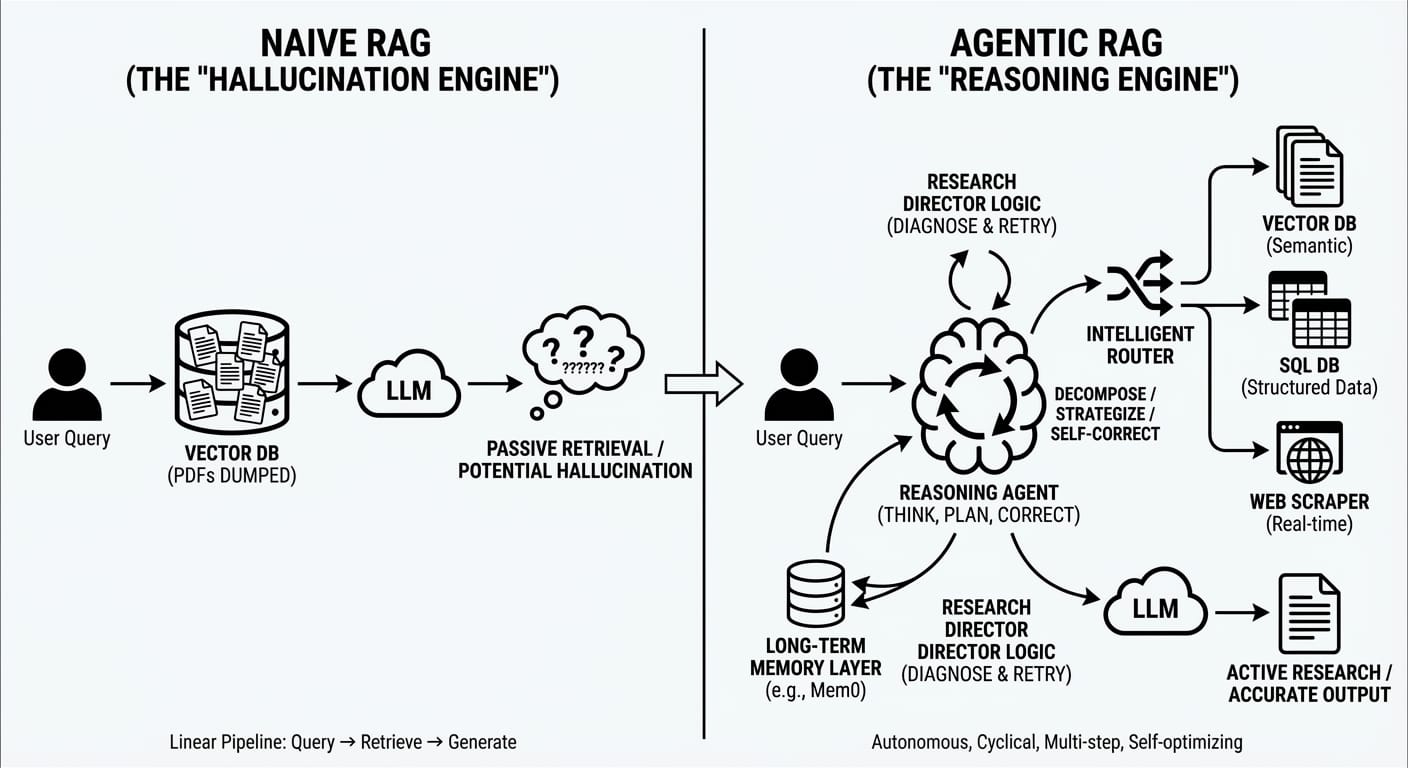
If your architecture still looks like "User Query $\to$ Vector DB $\to$ LLM," you aren’t building an AI application; you’re building a hallucination engine. The "naive" RAG era where we just dumped PDFs into Pinecone and prayed for the best is officially over.
We are entering the Agentic Era. The systems winning in 2025 aren’t passive retrievers; they are reasoning engines that think, plan, and correct themselves before they ever write a line of code.
Here is the technical reality of RAG in 2025.
1. The Shift to Agentic RAG
The most profound shift this year is the move from linear pipelines to autonomous agents. We are no longer building search bars; we are building researchers.
- Reasoning Over Retrieval: Modern architectures now employ a "thinking" layer. Instead of blindly querying a database, the system acts as a specialized agent. It decomposes complex user queries into sub-tasks, plans a research strategy, and executes multiple retrieval steps.
- The Self-Correcting Loop: Advanced agents use "Research Director" logic. If a retrieval step yields garbage, the agent acts like a human would: it diagnoses the weakness, rewrites the query, and tries again. It effectively optimizes its own SOPs in real-time.
- Intelligent Routing: Not every query needs a vector search. New routers classify intent immediately routing semantic questions to vectors, structured data requests to SQL, and real-time needs to web scrapers.
- Solving Amnesia: We are finally fixing the memory problem. By integrating long-term memory layers (like Mem0 or LangGraph), agents retain user context across sessions.
2. Data Engineering: The Death of OCR
"Garbage in, garbage out" is still the bottleneck, but the way we handle the "in" has changed massively.