Making Agentic Tool Usage 91% More Efficient: With JSON Response Filtering
Agentic systems call tools. Those tools return giant JSON blobs designed for booking engines, dashboards, or backend services—not for LLMs. The model usually needs a few fields; it still has to read everything.
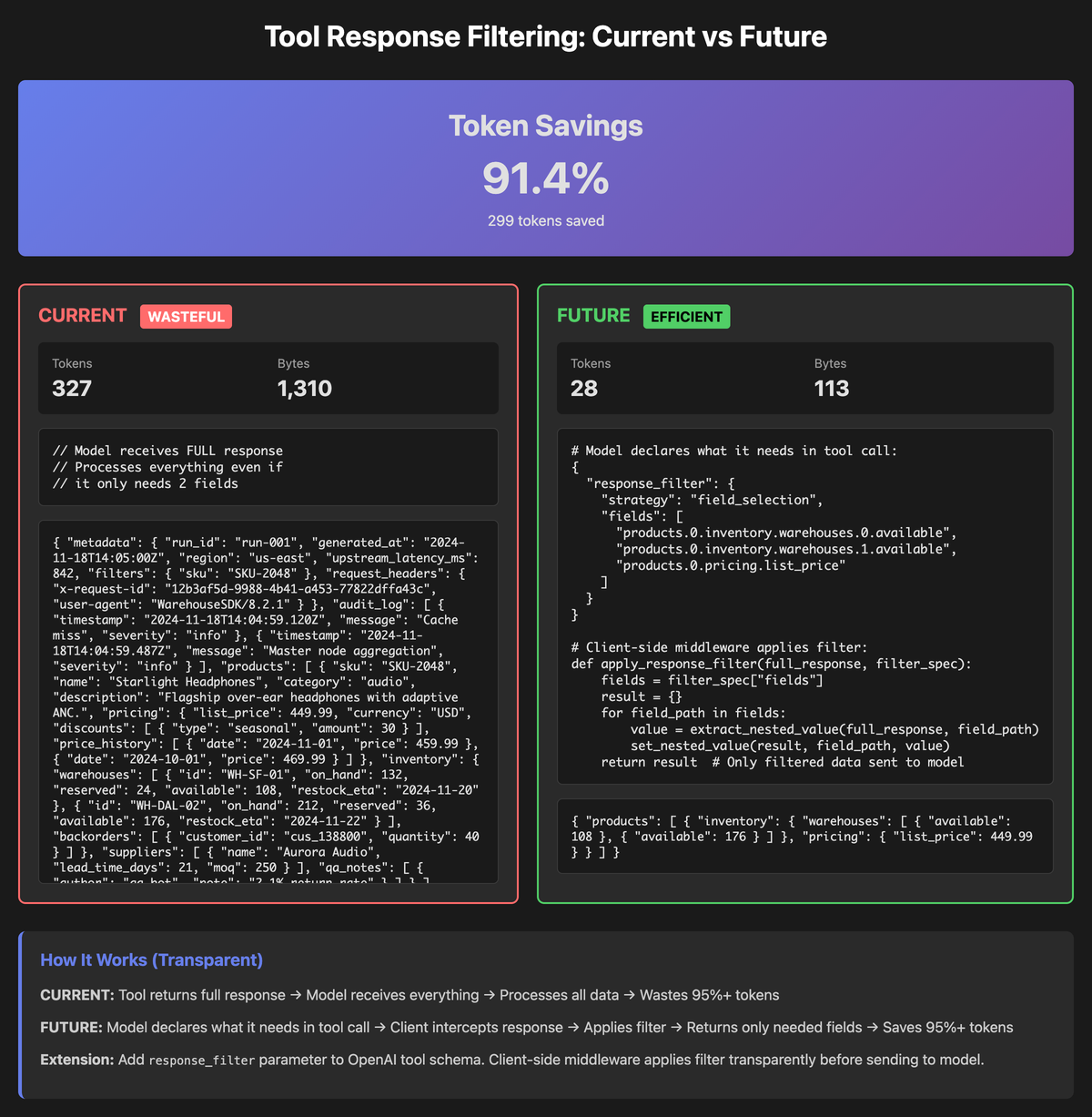
This describes a beta proof-of-concept: let the model say exactly which JSON fields it wants (via JSONPath), filter the tool response on the client, and only send the trimmed result into the model. In internal tests this cuts token usage by roughly an order of magnitude, without touching upstream APIs.
This is still beta, not production-ready.
The idea is simple enough to explain with one example: flight search.
The Problem: Flight Search APIs Are a Disaster for Agents
Take a typical flights API in the style of Amadeus. The agent asks:
“Find me the 5 cheapest economy flights from NYC to London on March 12. I only need departure time, arrival time, airline, and total price.”
What comes back is a huge, deeply nested JSON response built for a full booking stack. A single search can easily include:
- Dozens or hundreds of flight offers in a single response.
- One or more itineraries per offer (outbound, return, multi-city).
- Multiple segments per itinerary (legs) with marketing carrier, operating carrier, flight number, aircraft type, equipment codes, departure and arrival airports, terminals, timestamps, timezones, total duration, stopover airports, and layover durations.
- Detailed pricing per offer: total price, base price, taxes, currency, fare rules, per-traveler breakdowns (adult/child/infant), and optional services or ancillaries.
- Baggage rules: included allowances, paid options, weight vs piece concepts, overweight rules, and per-segment differences.
- Conditions and policies: refundability, changeability, penalties, restrictions, and brand fares.
- Extra metadata: validating carrier, booking codes, source systems, and other internal hints.
For the simple “top 5 cheapest flights” question, the agent might actually only need:
- Airline name or code.
- Departure airport and time.
- Arrival airport and time.
- Total price.
Everything else—hundreds of attributes per offer—is noise for this specific task. If you stream the raw tool response into the model, it still has to ingest and parse all of it.
That is the core problem: existing APIs expose everything; agents usually need almost nothing.
Why the Obvious Fixes Don’t Really Help
Before talking about the solution, it is worth being clear why “just fix the API” is not enough.
Redesigning or replacing APIs
In theory you could redesign your flight search API to return only what the agent needs. In reality you often do not own the API at all, or you share it with many other consumers (web, mobile, backend services) that depend on the current shape. Changing schemas is slow, political, and risky. You cannot realistically ask every provider you integrate with to ship an LLM-optimized version of their endpoints.
Wrapping everything in GraphQL
GraphQL lets clients request exactly the fields they want. That sounds perfect until you remember you need to build and maintain a GraphQL layer over every upstream system. For third-party APIs, you now own the entire schema mapping and maintenance burden. It does not help for tools you do not control or cannot easily wrap.
Code generation and “just write code instead of tools”
Code-generation approaches let the model generate code that calls APIs and shapes responses on the server side. This works, but it has limits. The model has to understand each API deeply enough to generate correct code up front. You also lose the very simple “tool call → result → think → next tool call” loop for many cases, and progressive exploration over a single response becomes clunky.
So we want something that:
- Does not require upstream API changes.
- Does not require GraphQL everywhere.
- Does not force everything into code generation.
- Still lets the model see a small, focused slice of a huge JSON response.
The Approach: Client-Side Dynamic Response Filtering (JSONPath)
The idea is to put a small, general filtering layer on the client side.
The model calls a tool and includes a response_filter in the tool call.
The client or middleware calls the real API (Amadeus-style flights, etc.) and receives the full JSON response.
The middleware applies the response_filter (JSONPath) to that JSON.
Only the filtered subset is sent back into the model’s context.
The API response is unchanged. The tool implementation is unchanged. The only new logic is the filter that runs between “tool finished” and “send result to model.”
Example: Asking for Top 5 Cheapest Flights Only
The model might generate a tool call like this (simplified):
{
"tool_calls": [
{
"id": "call_flights_1",
"type": "function",
"function": {
"name": "AmadeusAPI.search_flights",
"arguments": "{\"origin\": \"JFK\", \"destination\": \"LHR\", \"date\": \"2025-03-12\"}",
"response_filter": {
"strategy": "jsonpath",
"paths": [
"$.data[0:5].itineraries[0].segments[0].carrierCode",
"$.data[0:5].itineraries[0].segments[0].departure.iataCode",
"$.data[0:5].itineraries[0].segments[0].departure.at",
"$.data[0:5].itineraries[0].segments[-1:].arrival.iataCode",
"$.data[0:5].itineraries[0].segments[-1:].arrival.at",
"$.data[0:5].price.total"
]
}
}
}
]
}
Important details:
- The strategy is
jsonpath, so the filter is expressed entirely in JSONPath. pathsis just a list of JSONPath expressions over the raw flight search response.- This is generic; there is no tool-specific DSL or special protocol change.
On the client side, the middleware:
- Calls
AmadeusAPI.search_flightsas usual. - Receives the full response.
- Runs each JSONPath over that JSON.
- Rebuilds a minimal JSON payload containing only those fields.
- Returns that minimal payload to the model.
From the model’s perspective, it now sees a small, focused structure with only airline codes, departure and arrival info, and total prices for the top 5 offers. All baggage rules, fare conditions, and deep metadata never enter the model’s context for this question.
Where This Filtering Layer Actually Lives
You do not change the flight API. You do not change MCP servers. You put the JSONPath filter in the part of the stack that already sits between tools and the model.
In practice, that usually means one of these:
- Wrap the LLM client or SDK so that whenever a tool result comes back, the wrapper checks for
response_filter, applies the JSONPath expressions to the full JSON, and only then passes the trimmed response into the model. - Add middleware in your agent framework’s “execute tool” step; the framework calls the tool, your middleware intercepts the raw JSON result, applies the JSONPath filter requested by the model, and hands only the filtered data to the agent’s reasoning loop.
- Implement filtering inside the MCP host or client; it receives full tool results from MCP servers, applies the model’s JSONPath filters on those results, and returns only the filtered payload to the model, leaving MCP servers completely unaware of the filtering logic.
In all cases the pattern is the same: the model requests specific fields, the middleware trims the response to exactly those fields, and the model never sees the rest.
What You End Up With
With this pattern you still have the same upstream APIs, the same tools and MCP servers, and the same agent loop. The only change is at the boundary where tool results are fed back into the model.
Instead of streaming a giant flight search response into the model and hoping it mentally filters out most of it, you:
- Let the model say “I only need these JSONPath paths.”
- Apply that filter client-side.
- Only send the relevant slice of the data into the model’s context.
In practice this means far fewer tokens per tool call, less time streaming JSON, less context bloat, and better focus on the values that actually matter for the current task. When you genuinely do need the full response, you can simply omit or relax the filter for that call.
What Has to Change for This to Go Mainstream
Right now this is a client-side pattern you can implement in your own stack. To unlock the next tier of real-world use cases, the hosts that already mediate tools for models would need to adopt something like this as a first-class capability.
That means:
- MCP-capable clients and hosts (desktop apps, browser-based chat, IDE agents, and similar environments) need to let the model attach a
response_filterto tool calls and treat that as part of the tool invocation contract. - Those clients and hosts need to apply JSONPath or an equivalent selection mechanism to the full tool result before it is fed back into the model, instead of streaming raw tool payloads directly into the context.
- Tool ecosystems like ChatGPT tools, Claude tools, IDE and workflow agents, and other multi-tool hosts need to expose this filtering behavior in their tool runtime layer, not in every individual tool.
If mainstream LLM hosts start honoring model-specified filters and doing efficient, selective tool result shaping by default, you can suddenly plug in real-world APIs like Amadeus, Salesforce, Shopify, internal inventory systems, or huge scrapers without overwhelming the model. Agents stop drowning in irrelevant JSON and start behaving like they actually belong on top of complex, noisy systems.
The underlying APIs do not have to change. The tools do not have to change. The host that sits between “tool result” and “LLM context” just has to get smarter about only sending what the model actually asked for.