OpenAI’s New Predicted Outputs is a Game Changer
OpenAI's new **Predicted Outputs** feature optimizes API response times by reusing predictable output content. Ideal for minor updates, like changing styles, it can reduce completion times by up to 66% while significantly lowering costs. However, its effectiveness diminishes with extensive change...

OpenAI recently introduced a powerful feature called Predicted Outputs that can significantly reduce latency in API responses when much of the output content is predictable. Let's explore this feature through practical examples.
Understanding Predicted Outputs
When modifying text or code files where only small changes are expected, we can provide a prediction of what we think the output will be. The model can then use this prediction to generate responses faster by reusing parts of our prediction that match its intended output.
For more details, see the official OpenAI documentation.
Real-World Examples
Let's look at two examples that demonstrate when Predicted Outputs are most and least effective.
Example 1: Minor Style Change
In this example, we simply want to change the background color to green. This is an ideal case for Predicted Outputs since most of the code remains unchanged.
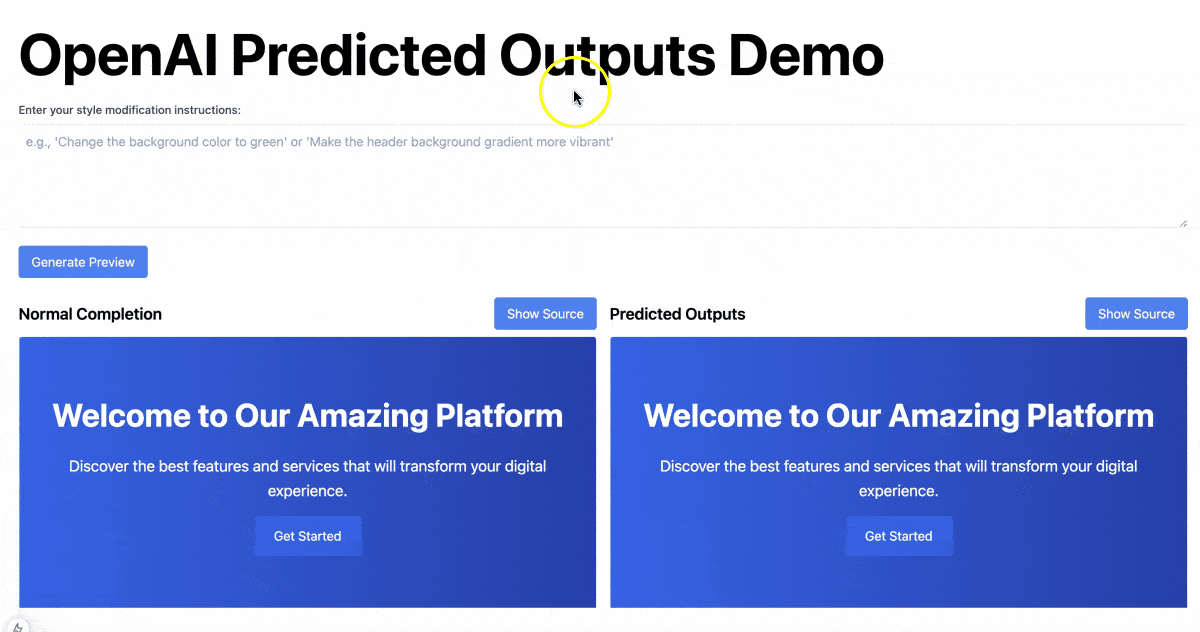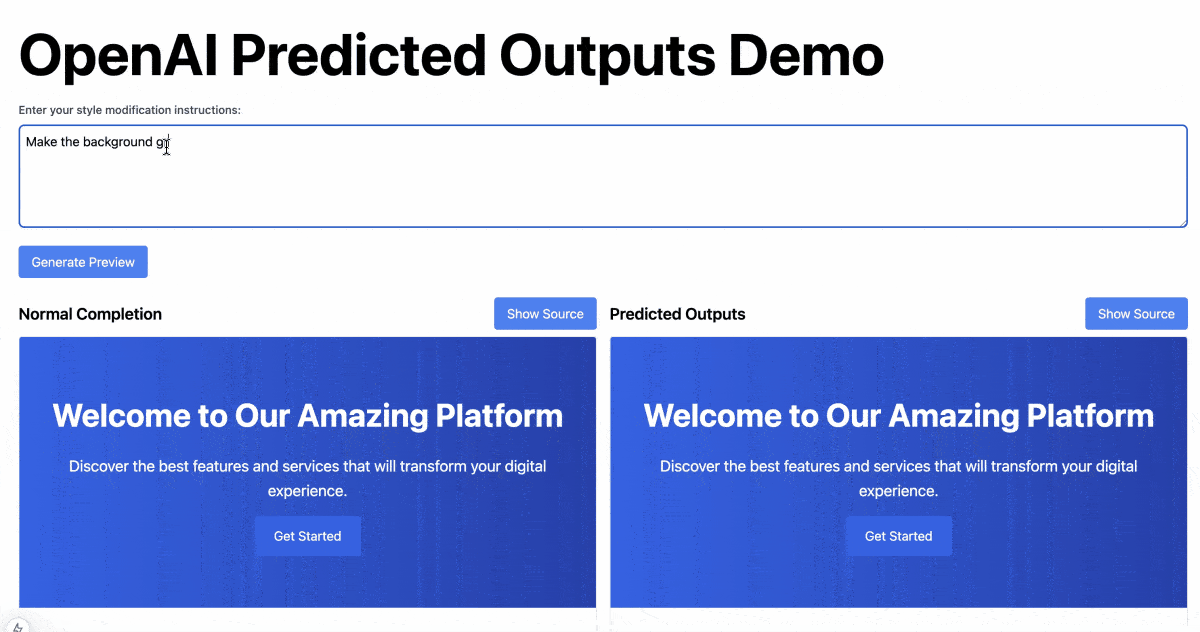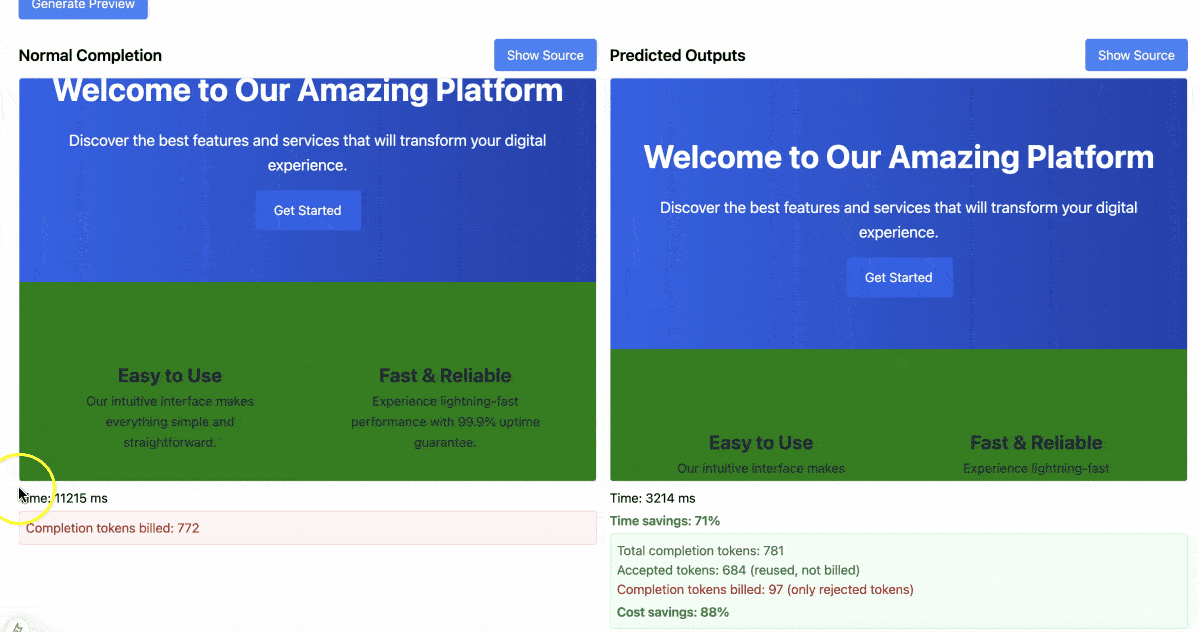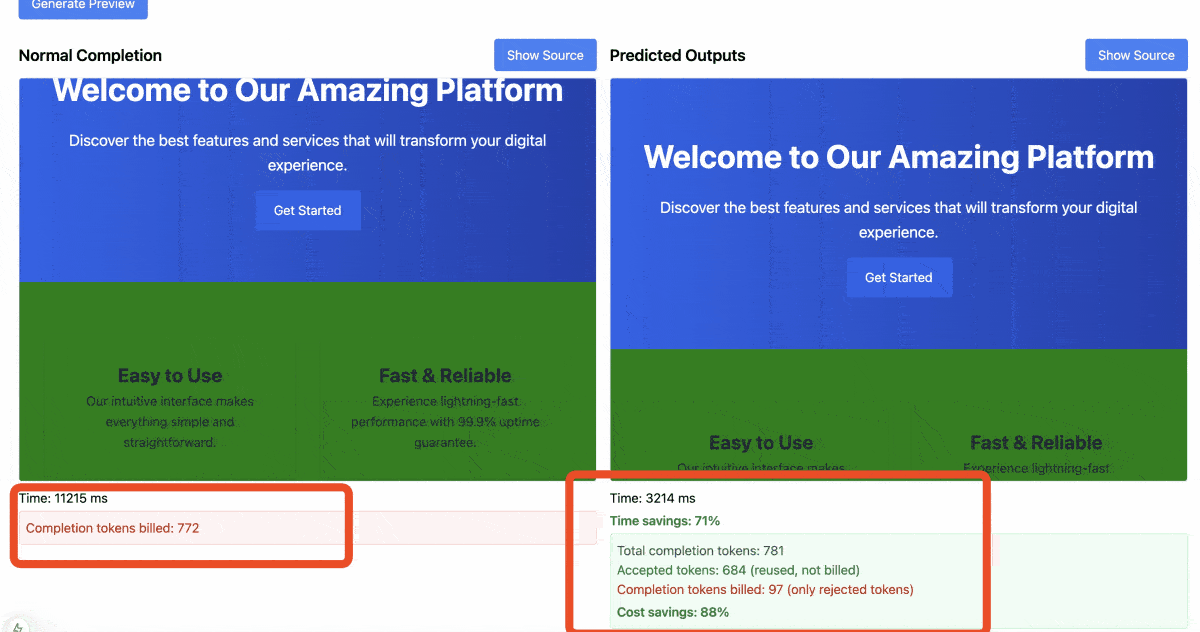
Results:
- Normal Completion Time: 14,115 ms
- Predicted Outputs Time: 4,756 ms
- Time Savings: 66%
- Total Completion Tokens: 784
- Accepted Tokens: 686 (reused, not billed)
- Completion Tokens Billed: 98 (only rejected tokens)
- Cost Savings: 88%
- Tokens per Second (Normal): Approximately 55 tokens/sec
- Tokens per Second (Predicted Outputs): Approximately 165 tokens/sec
This demonstrates the power of Predicted Outputs when changes are minimal. Most of the original content was reused, resulting in significant time and cost savings, and a substantial increase in tokens processed per second.
Please note that due to the nature of randomness in token prediction, there is always a difference, so the small difference above may change slightly or even become negative in further predictions.
Example 2: Complete Style Overhaul
In this second example, we completely change the styling and content of the page. This represents a case where Predicted Outputs offers minimal benefit since most content needs to change.
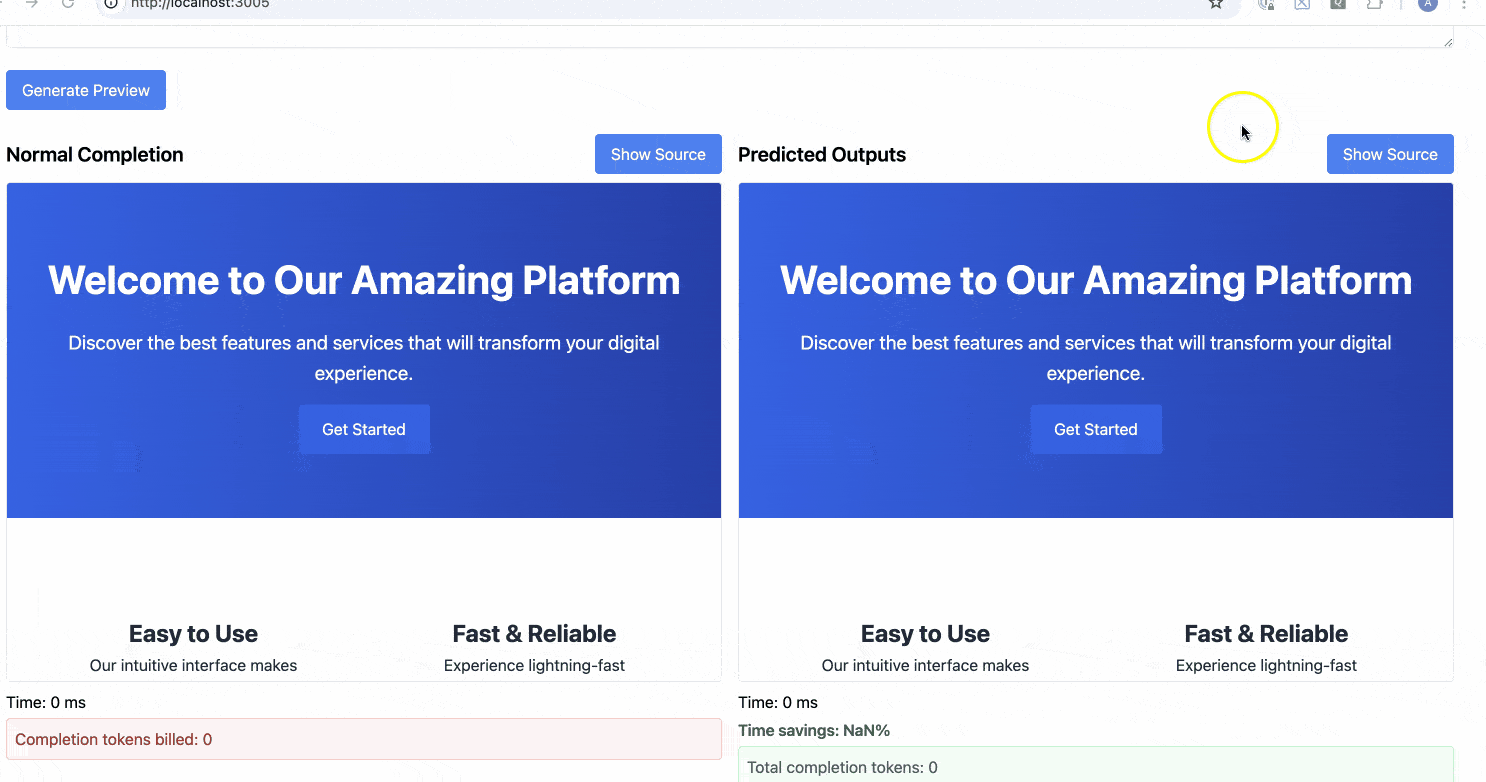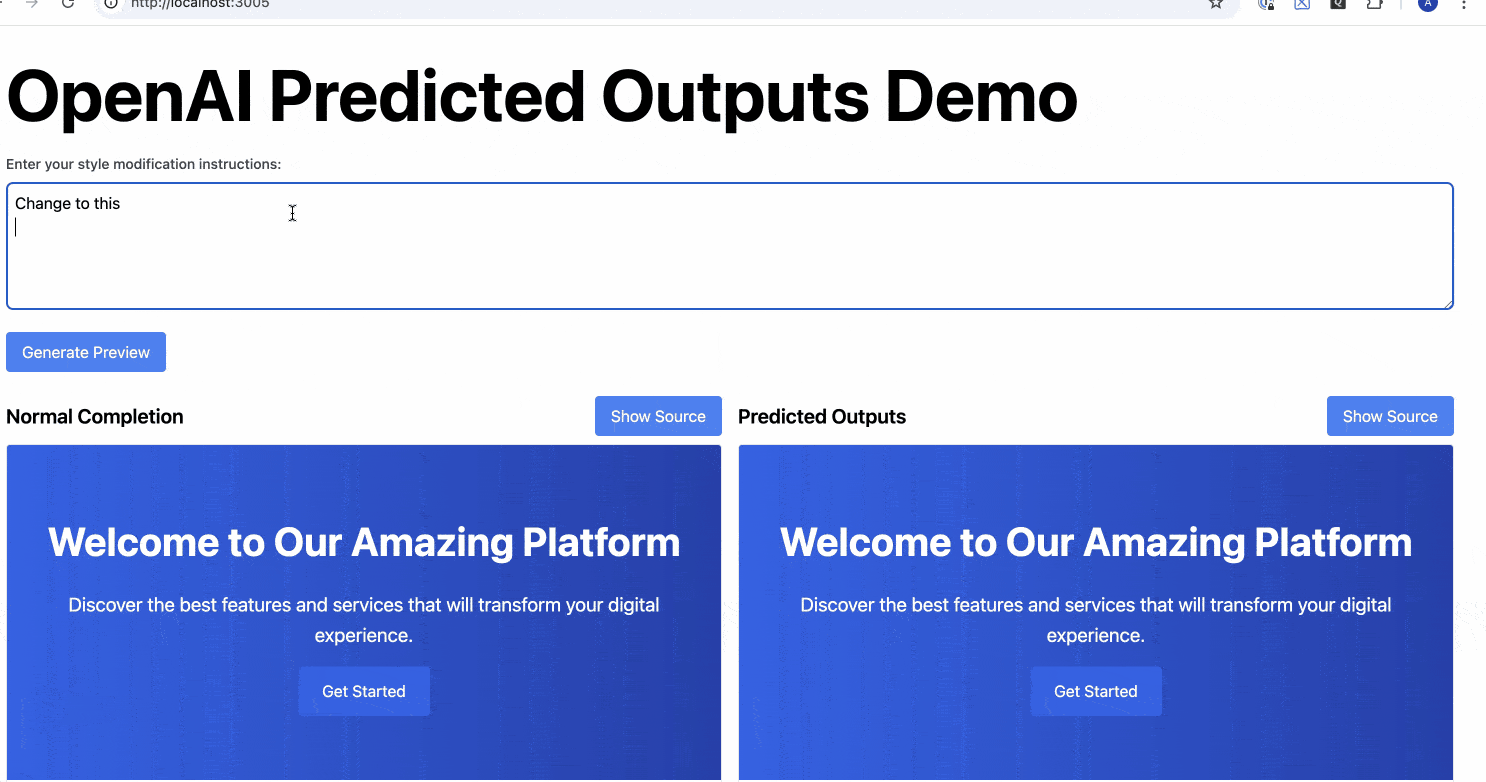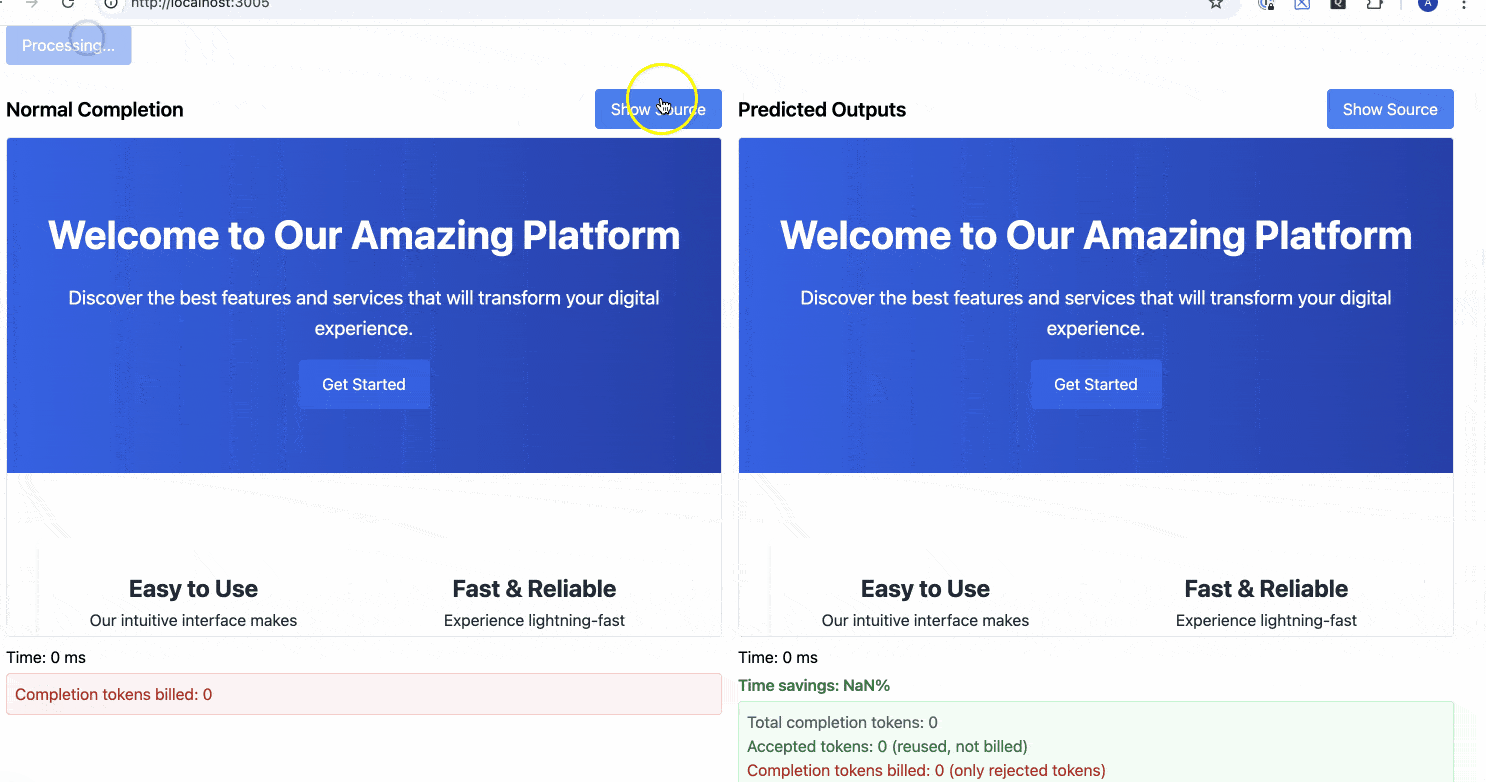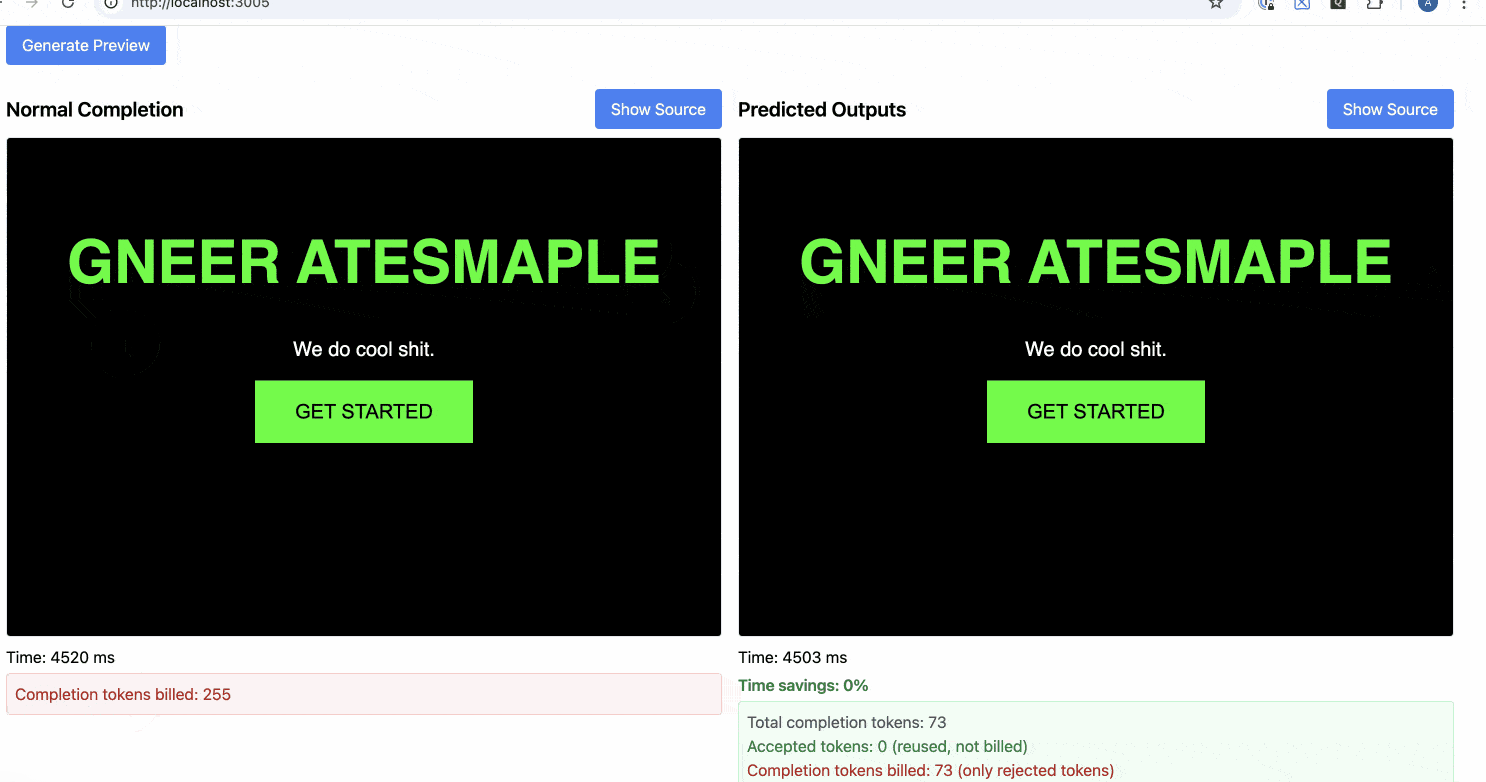
Results:
- Normal Completion Time: 3,717 ms
- Predicted Outputs Time: 3,509 ms
- Time Savings: 6%
- Total Completion Tokens: 73
- Accepted Tokens: 0 (reused, not billed)
- Completion Tokens Billed: 73 (only rejected tokens)
- Cost Savings: 0%
- Tokens per Second (Normal): Approximately 19.6 tokens/sec
- Tokens per Second (Predicted Outputs): Approximately 20.8 tokens/sec
When the changes are extensive, the prediction doesn't help much since most tokens need to be regenerated anyway. The slight improvement in tokens per second is negligible.
Implications and Use Cases
Potential Benefits
- Reduced Latency: By reusing predicted tokens, response times can be significantly decreased, enhancing user experience in applications requiring quick feedback.
- Cost Efficiency: Since accepted predicted tokens are not billed, overall costs can be reduced, especially in applications with frequent minor updates.
- Increased Throughput: Higher tokens per second mean that more data can be processed in less time, beneficial for large-scale operations.
Ideal Use Cases
- Code Refactoring: Making small adjustments to large codebases where most of the code remains unchanged.
- Document Editing: Applying minor edits to lengthy documents, such as correcting typos or updating specific sections.
- Format-Preserving Transformations: Converting documents between formats (e.g., HTML to Markdown) where the structure is predictable.
- Template-Based Responses: Generating responses where the output format is consistent, such as emails, reports, or standardized messages.
Limitations
- Prediction Accuracy: The effectiveness of Predicted Outputs heavily relies on the accuracy of the prediction. Inaccurate predictions can lead to increased costs due to rejected tokens.
- Limited Use Cases: Not beneficial for tasks involving significant content changes or creative generation where the output is largely unpredictable.
- Model Support: Currently supported only on specific models like GPT-4o and GPT-4o-mini series.
Implementation Tips
- Monitor Token Usage: Keep an eye on accepted vs. rejected prediction tokens to assess the effectiveness of your predictions and adjust accordingly.
- Optimize Predictions: Use the original content as the prediction when making small modifications to maximize accepted tokens.
- Leverage Streaming: Stream results as they arrive for a better user experience and to capitalize on latency gains.
- Parallel Testing: Run normal and predicted completions in parallel during testing phases to compare performance and fine-tune your approach.
Conclusion
OpenAI's Predicted Outputs feature can offer significant performance benefits, especially in scenarios involving minor changes to large amounts of content. By reusing predictable output, it reduces latency, cuts costs, and increases tokens processed per second. However, its effectiveness varies based on the use case. Understanding these characteristics helps in deciding when to leverage this feature for optimal results.



