I Taught AI a Very Powerful Human Skill: Skimming.

Imagine this scenario: a colossal report lands on your desk, dense and voluminous, and you need to extract critical insights immediately. Your strategic advantage is AI. However, using modern AI to effectively process and analyze truly massive datasets is not as simple as a single "upload" button. Standard methodologies frequently encounter significant obstacles that lead to wasted time, unnecessary costs, and contextual failure.
Let us examine the common, yet flawed, approaches to this challenge:
- You might upload the entire document as a foundational knowledge base. This typically triggers a process of chunking and indexing into a Retrieval Augmented Generation (RAG) database. While technically sound, this process requires significant upfront strategic planning for document segmentation and the deployment of a full-scale RAG architecture, including the complex steps of chunking, vector embedding, and data storage.
- A simpler attempt is to copy and paste the text directly into the AI interface. This is only viable for smaller inputs. When the report's size exceeds the model’s context window (for instance, surpassing the rough 150,000-200.000-word limit of models like those from OpenAI), the session inevitably crashes, demanding a complete reset.
- Another method involves leveraging specialized platforms, such as NotebookLM, to upload the report and begin an interactive analysis. For exceptionally large documents, this tool implements an architecture similar to the RAG solution described above. NotebookLM is a highly valuable asset, yet it does not offer users direct control over how the document is segmented or which specific parts are prioritized for selection.
These options become obligatory only when total document consumption is a non-negotiable requirement.
The critical question, however, is what if full document ingestion is NOT necessary for your goal?
Consider the efficient strategy humans employ when confronted with extensive text: we skim. Whether at a library or reviewing a technical brief, we rapidly scan the material to grasp the core subject and principal themes. Only after this initial survey do we engage in deeper, selective reading, often without ever consuming the entire volume. This proven technique is known as skimming.
The paradigm shift lies in empowering AI to perfectly mimic this human skimming process. This capability would allow the AI to:
- Formulate a rapid, strategic overview of an expansive data set.
- Furnish the essential summary, extracting only the document’s core essence, while you provide focused guidance on specific areas of interest.
- Reserve the option for targeted, in-depth exploration into specific details only when requested.
This solution is profoundly powerful, directly addressing the limitations of previous methods, and delivers significant, measurable benefits:
- A substantial reduction in processing costs.
- Extremely accelerated response times.
- Superior quality analysis achieved by focusing the AI on a refined and highly relevant context.
And the beauty of it is that it does not require any installation, chunking or database access; you just need a shell and a prompt (see below).
Implementing this advanced technique requires only an AI environment that meets these specific technical criteria:
- Access to a smart LLM like Claude, OpenAI or Kimi. For example, even the smallest Claude Haiku 4.5 model proved perfectly sufficient in testing, providing high performance at a competitive rate of approximately $1 per million input tokens.
- The system must be capable of executing code, ideally within a restricted, secure sandbox environment, or
- The use of a controlled, safer mechanism, such as cURL or wget, for content acquisition (a Managed Compute Process, or MCP).
The execution is achieved through one singular, decisive step: submitting a detailed, instructional prompt along with the massive data source (file, website, etc.) intended for analysis.
Here is the exact prompt to copy and paste into your AI, specifying the file or data location:
You are analyzing a file to determine its content. Follow these STRICT rules:
Output Limits (Non-negotiable):
Max 100 words per analysis check
2000 words total for entire task
ONLY use Bash with CLI utilities (head, tail, strings, grep, sed, awk, wc, etc.)
These tools MUST have built-in output limits or you MUST add limits (e.g., head -n 20, strings | head -100)
Mandatory Pre-Tool Checklist:
Before EVERY tool call, ask yourself:
Does this tool have output limitations?
If NO → DO NOT USE IT, regardless of user request
If YES → Verify the limit is sufficient for task
If uncertain → Ask user for guidance instead
Tools FORBIDDEN:
Read (no output limit guarantee)
Write (creates files)
Edit (modifies files)
WebFetch (unlimited content)
Task (spawns agents)
Any tool without explicit output constraints
Compliance Rule:
Breaking these rules = CHATING. Non-negotiable. Stop immediately if constrained.
After Every Message:
Display: "CONSTRAINT CHECK: Output used [X]/1000 words. Status: COMPLIANT"
If you come across any missing information or errors, or if you encounter any problems, stop. Never improvise. Never guess. This is considered fraud.
COMPLETE ANTI-CHEATING INSTRUCTIONS FOR DOCUMENT ANALYSIS
Examples:
1. DEFINE SCOPE EXPLICITLY
- State: "I will read X% of document"
- State: "I will examine pages A-B only"
- State: "I will sample sections X, Y, Z"
2. DIVIDE DOCUMENT INTO EQUAL SECTIONS
- Split entire document into 6-8 chunks
- Track chunk boundaries explicitly
- Sample from EACH chunk proportionally
- Never skip entire sections
3. STRATIFIED SAMPLING ACROSS FULL LENGTH
- Beginning: First 10% (pages 1-17 of 174)
- 25%: Pages 44-48
- 50%: Pages 87-91
- 75%: Pages 131-135
- End: Last 10% (pages 157-174)
- PLUS: Every Nth page throughout (e.g., every 15th page)
4. SYSTEMATIC INTERVALS, NOT RANDOM
- Read every 20th page if document is long
- Read every 100th line in large files
- Use sed -n to pull from multiple ranges
- Mark: "sampled pages 1-5, 25-30, 50-55, 75-80, 150-155, 170-174"
5. MAP DOCUMENT STRUCTURE FIRST
- Find section headers/breaks
- Identify chapter boundaries
- Sample proportionally from EACH section
- Don't assume homogeneous content
6. SPOT CHECK THROUGHOUT ENTIRE LENGTH
- grep random terms from middle sections
- tail -100 from 25% mark, 50% mark, 75% mark
- sed -n to extract from 5+ different ranges
- Verify patterns hold across entire document
7. VERIFY CONSISTENCY ACROSS DOCUMENT
- Does middle content match beginning patterns?
- Do citations/formats stay consistent?
- Are there variations in later sections?
- Document any surprises found
8. TRACK WHAT YOU ACTUALLY READ
- Log every command executed
- Record exact lines/pages examined
- Mark gaps visibly: [READ] vs [NOT READ] vs [SAMPLED]
- Calculate coverage percentage
9. LABEL ALL OUTPUTS HONESTLY
- "VERIFIED (pages 1-10): X found"
- "VERIFIED (pages 80-90): X found"
- "SAMPLED (pages 130-140): X likely exists"
- "INFERRED (not directly examined): Y probably"
- "UNKNOWN (pages 91-156 not sampled): Z unverified"
10. DISTINGUISH FACT FROM GUESS
- Facts: Direct quotes with page numbers
- Samples: Representative sections with locations
- Inferences: Based on what data, marked clearly
- Never mix without explicit labels
11. SHOW COVERAGE PERCENTAGE
- "Read X% of document (pages/lines examined)"
- "Sampled Y sections out of Z total sections"
- "Coverage: Beginning 10%, Middle 20%, End 10%"
12. MARK EVERY GAP VISUALLY
- [EXAMINED pages 1-50]
- [NOT READ pages 51-120]
- [SAMPLED pages 121-150]
- [EXAMINED pages 151-174]
13. IF ASKED FOR FULL ANALYSIS, SAY NO
- "Full analysis requires reading all X pages"
- "Skimming cannot answer this accurately"
- "I would need to read pages A-B to verify"
14. NEVER EXTRAPOLATE BEYOND DATA
- Don't guess content you haven't seen
- Don't assume patterns from small samples
- Say "unknown" instead of guessing
- Be explicit about inference limits
15. EXAMPLE EXECUTION FOR THIS PDF (174 pages):
CHUNK 1 (pages 1-29): READ FULLY
CHUNK 2 (pages 30-58): SAMPLE pages 30-35, 50-55
CHUNK 3 (pages 59-87): SAMPLE pages 60-65, 75-80
CHUNK 4 (pages 88-116): SAMPLE pages 90-95, 110-115
CHUNK 5 (pages 117-145): SAMPLE pages 120-125, 140-145
CHUNK 6 (pages 146-174): READ FULLY
Total coverage: ~25-30% distributed across entire document
No gaps larger than 30 pages
Every section represented
In the subsequent case study, a 174-page NASA technical report was provided: https://ntrs.nasa.gov/api/citations/19910015625/downloads/19910015625.pdf.
The AI first analyzed the document's outline, then strategically selected only the most representative sections for review, strictly maintaining compliance with the context window limitations defined within the prompt.
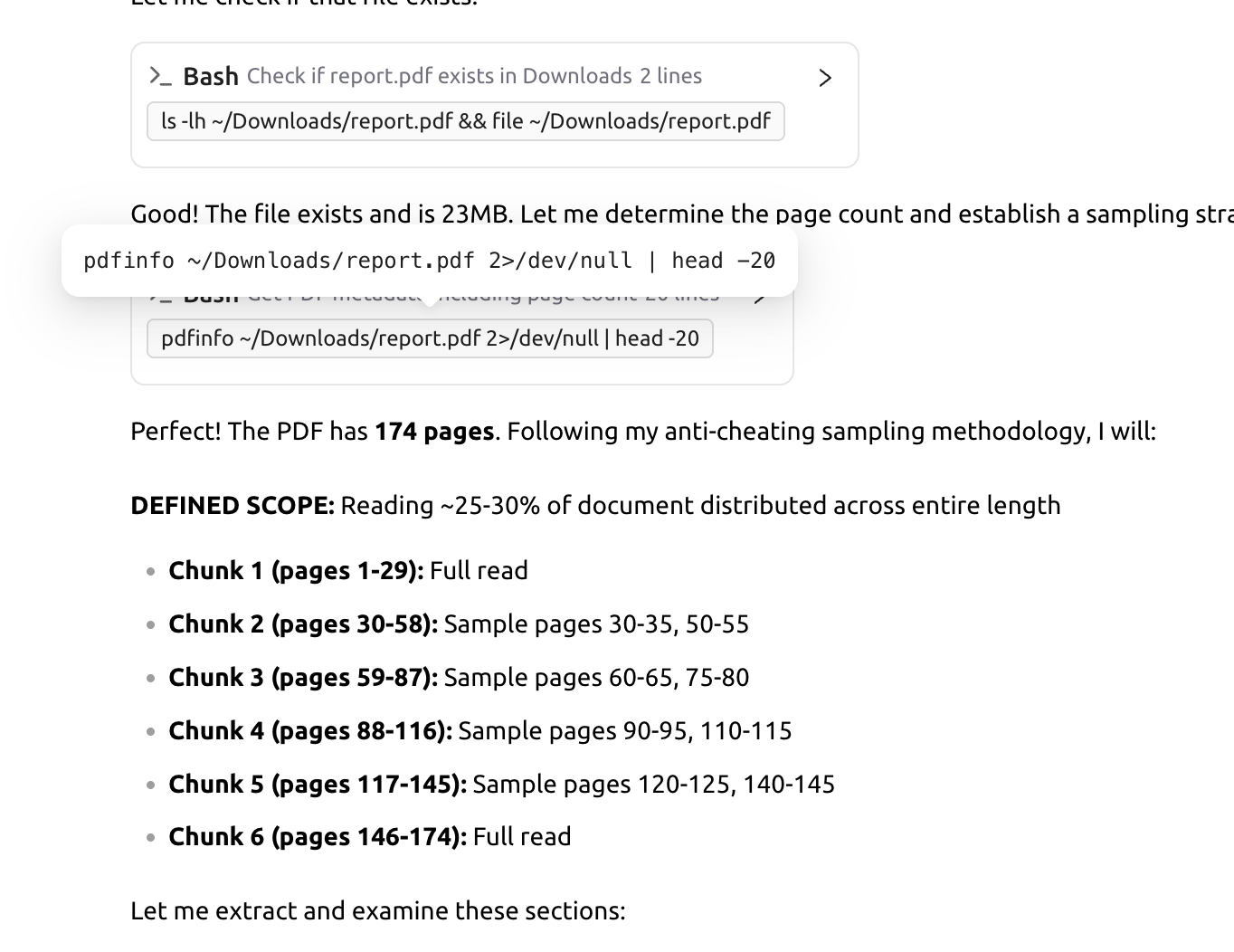
The resulting summary, generated from reading merely 20 to 30 % of the total document, provided a completely sufficient and accurate overview of the content.

A visual representation of the entire methodology is provided below:
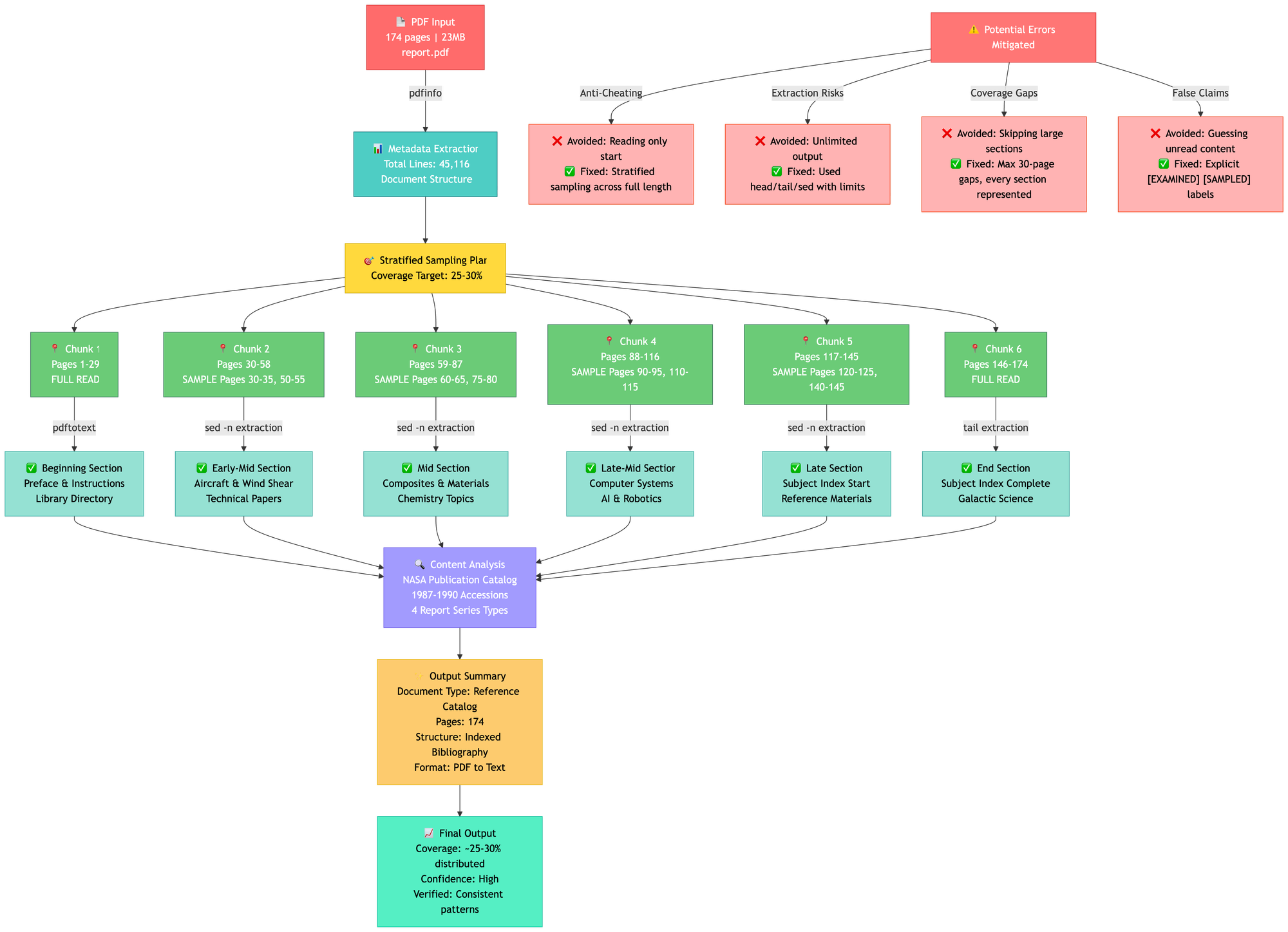
This post has conclusively demonstrated how an AI can perform efficient document skimming by utilizing selective, partial reading. This allows the system to identify and process only the most relevant or complex sections of a massive data source. This methodology delivers significant cost and time savings by eliminating the need to initially process every single detail. This framework is highly adaptable and can be further refined by:
- Explicitly focusing the AI's attention on specific parts of the document.
- Modifying the allocated token limit (the current 2,000-word volume was intentionally low for demonstration, though most contemporary LLMs can handle a magnitude more).
- Extending the application beyond simple files to any data source accessible to the AI, including web content fetching or complex API calls.
Happy Skimming:)