RAG's Holy Grail
Explore the power of Retrieval-Augmented Generation (RAG) solutions in our latest post! We delve into a tool that autonomously updates content, eliminating the hassle of manual uploads. Learn how to set it up with Docker, test document updates, and enhance your document intelligence effortlessly....


There are a lot of RAG (Retrieval-Augmented Generation) solutions out there that make it incredibly easy to use AI to extract intelligence from existing document sources.
However, many of them only offer user-triggered content updates using an API or UI such as Open WebUI or AnythingLLM.
But what if that content changes over time?
In this case the user has to open a UI and upload the changed documents or delete the older ones. Of course, they could also use an API to automate this process. But that could be time-consuming.
What if the RAG solution could simply detect these changes itself and update the embeddings?
This is exactly what we are going to talk about in this post, using one of the open source tools that tries to address this problem.
Here is the link to the Github repository
So let's try it with some common use cases:
Outline
- Cloning the Repository
- Creating an Environment File
- Running Docker
- Testing the Framework
- Querying Current Content
- Adding New Content
- Deleting Content
Quick Start by Running in Docker
1. Cloning the Repository
git clone https://github.com/pathwaycom/llm-app.git
cd examples/pipelines/demo-question-answering2. Creating a .env File
Create a .env file in the same folder and add your OpenAI API key:
OPENAI_API_KEY=sk-xxxx3. Running Docker
Run the following Docker command:
docker run --env-file .env -v `pwd`/data:/app/data -p 8000:8000 qaNote that the documents being continuously embedded are now in the data folder in the example directory above. Any files added to this folder (locally) are automatically embedded and can be used for question answering.
The running Docker container can be queried using the API as described here.
4. Testing the Framework
To test the Framework, we will check the embedding statistics and query the current content. We will also add and delete content to verify that the system automatically updates.
Test 1: Querying Current Content
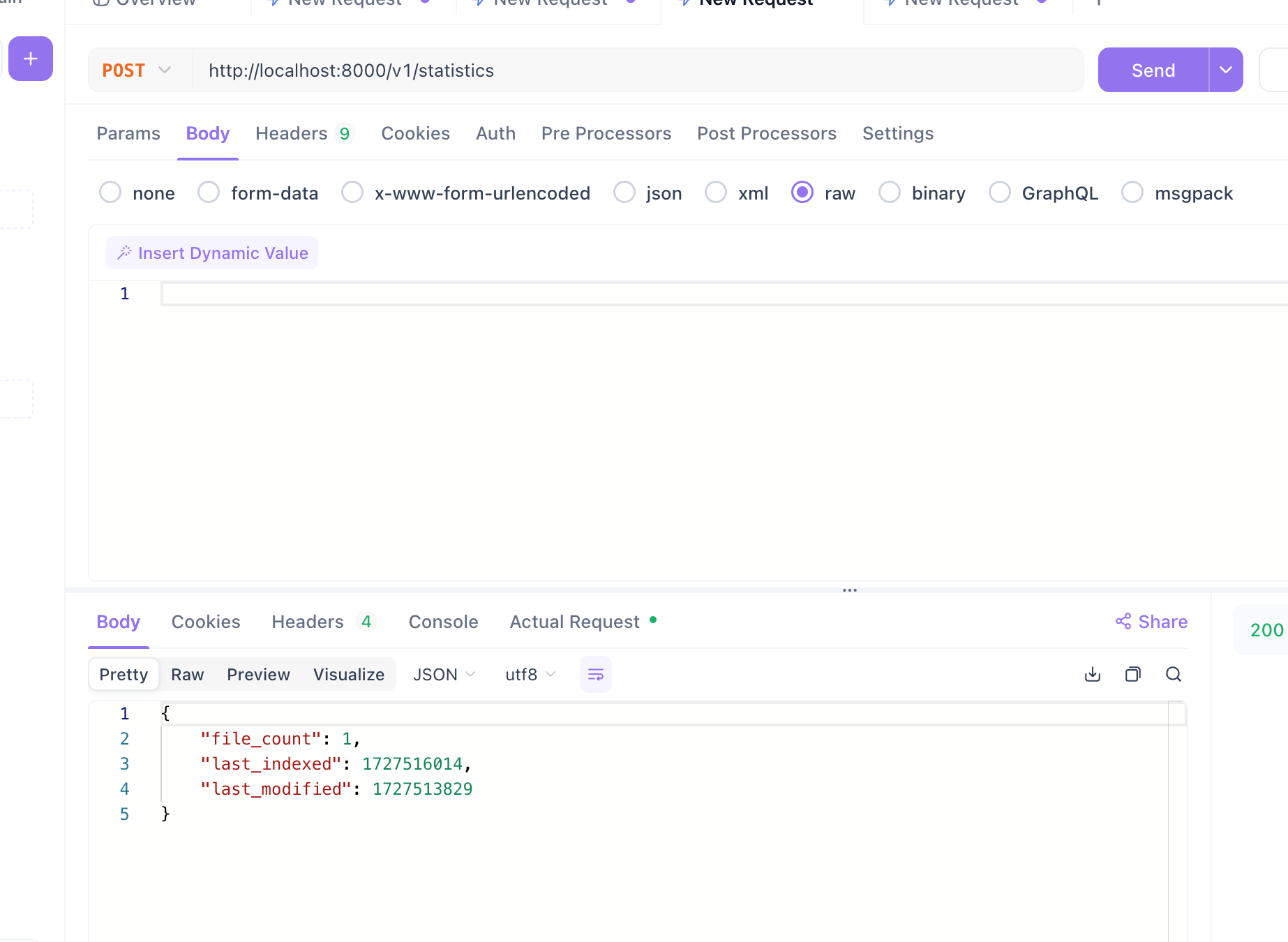
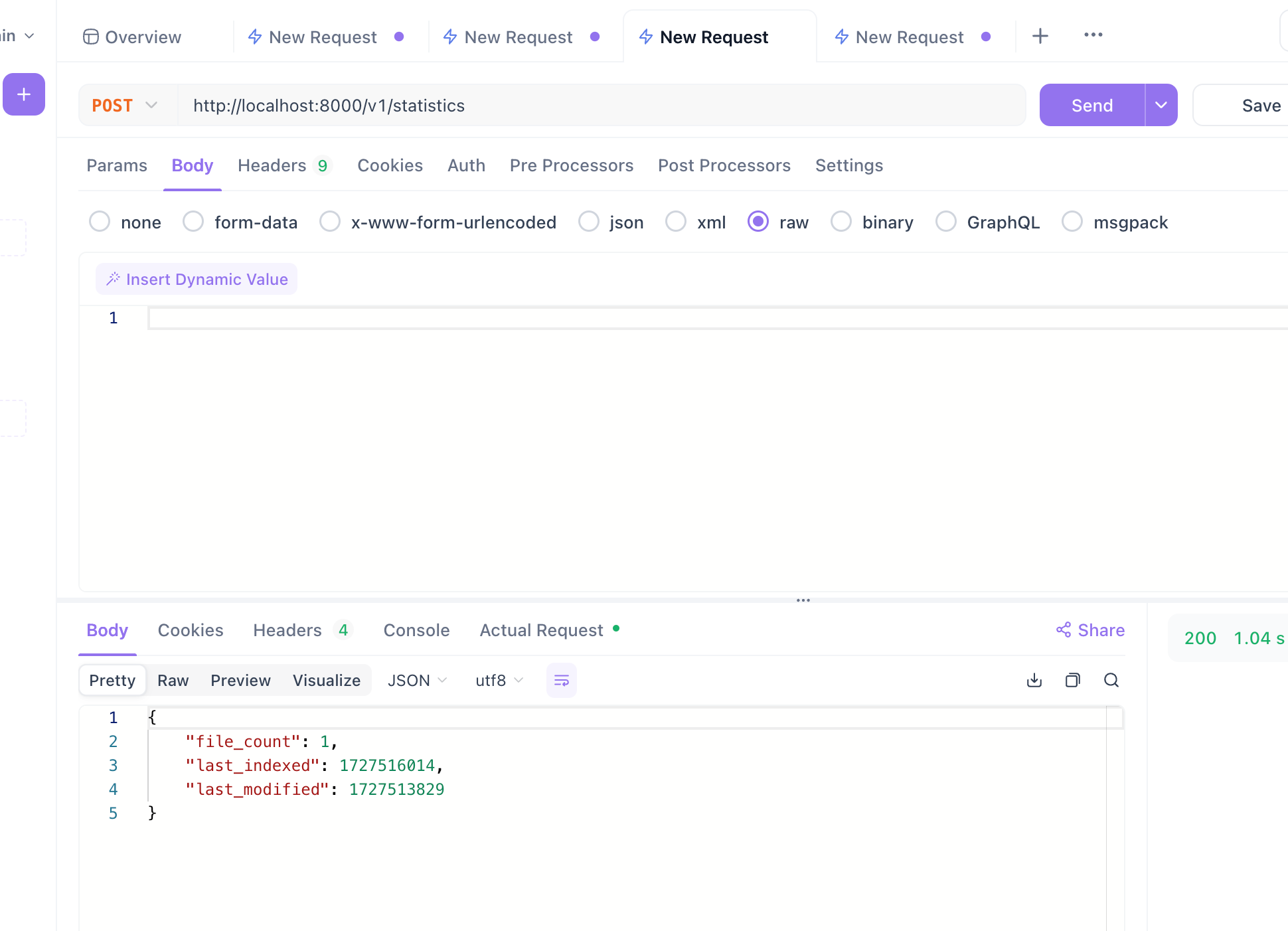
First, check the current statistics:
curl -X 'POST' 'http://localhost:8000/v1/statistics' -H 'accept: */*' -H 'Content-Type: application/json'If you look in the data folder, you’ll see one file. The call returns exactly what is in that file.
Let’s ask a question about this file (a contract):
curl -X 'POST'\
'http://0.0.0.0:8000/v1/retrieve'\
-H 'accept: */*'\
-H 'Content-Type: application/json'\
-d '{
"query": "What is the start date of the contract?",
"k": 2
}'The answer should be correct, as shown below:
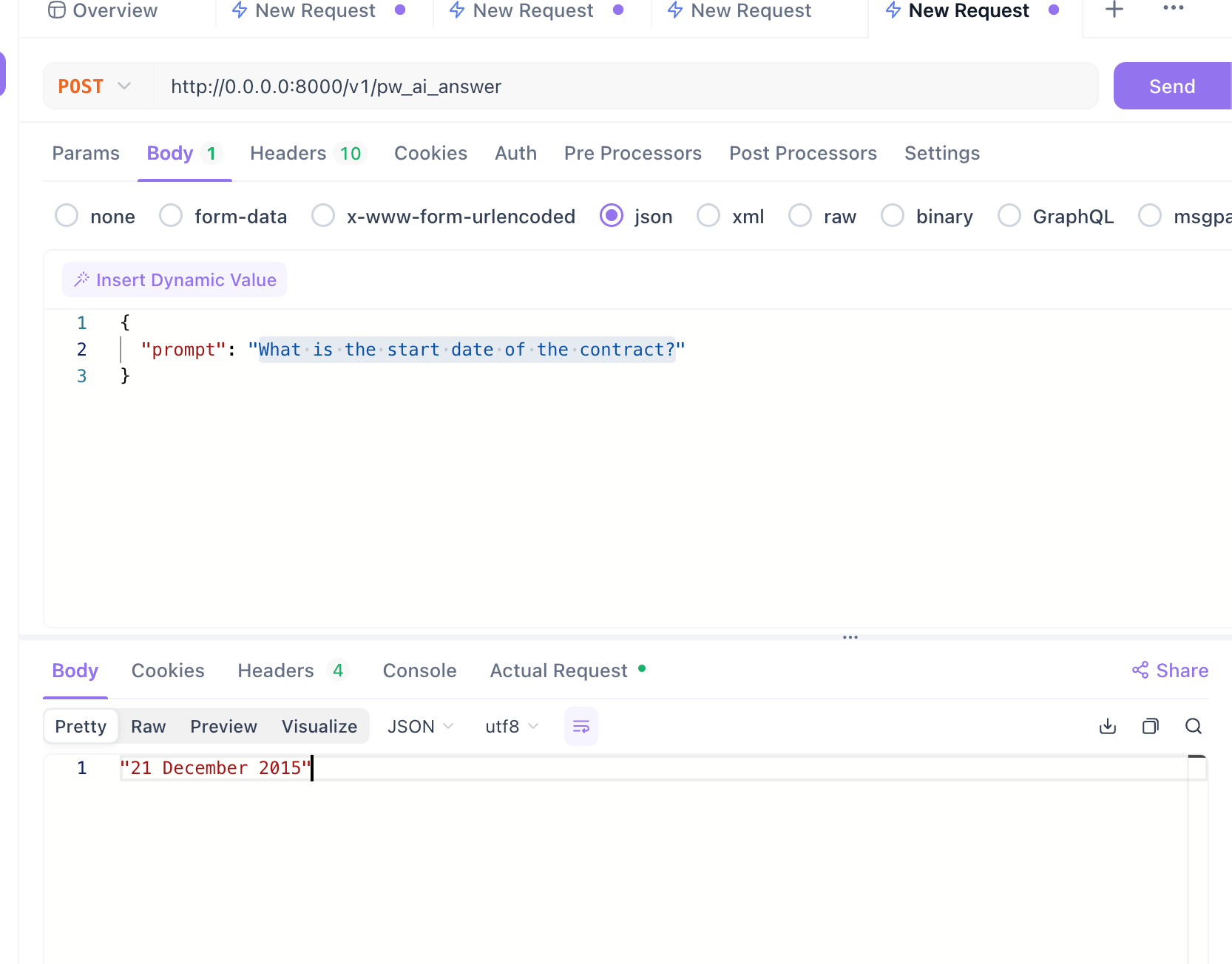
Looks good.
Test 2: Adding a New File
Next, let's add a new file and see if the tool notices and embeds it automatically. I created a file about a fictitious company and added it to the data folder:
TechNova Solutions is a cutting-edge technology firm that specializes in developing innovative artificial intelligence systems for sustainable urban planning. Founded in 2019 by Dr. Peter Müller and Marcus Blackwood, the company has quickly risen to prominence in the tech industry.
Based in the heart of Silicon Valley, TechNova's headquarters is a marvel of modern architecture, featuring living walls, solar panels, and an open-concept design that fosters creativity and collaboration. The company employs over 200 talented individuals from diverse backgrounds, including data scientists, urban planners, and environmental engineers.
Let’s see how many files the stats now show. After a few seconds, running the same stats curl command in API Dog, we get the expected number: 2.
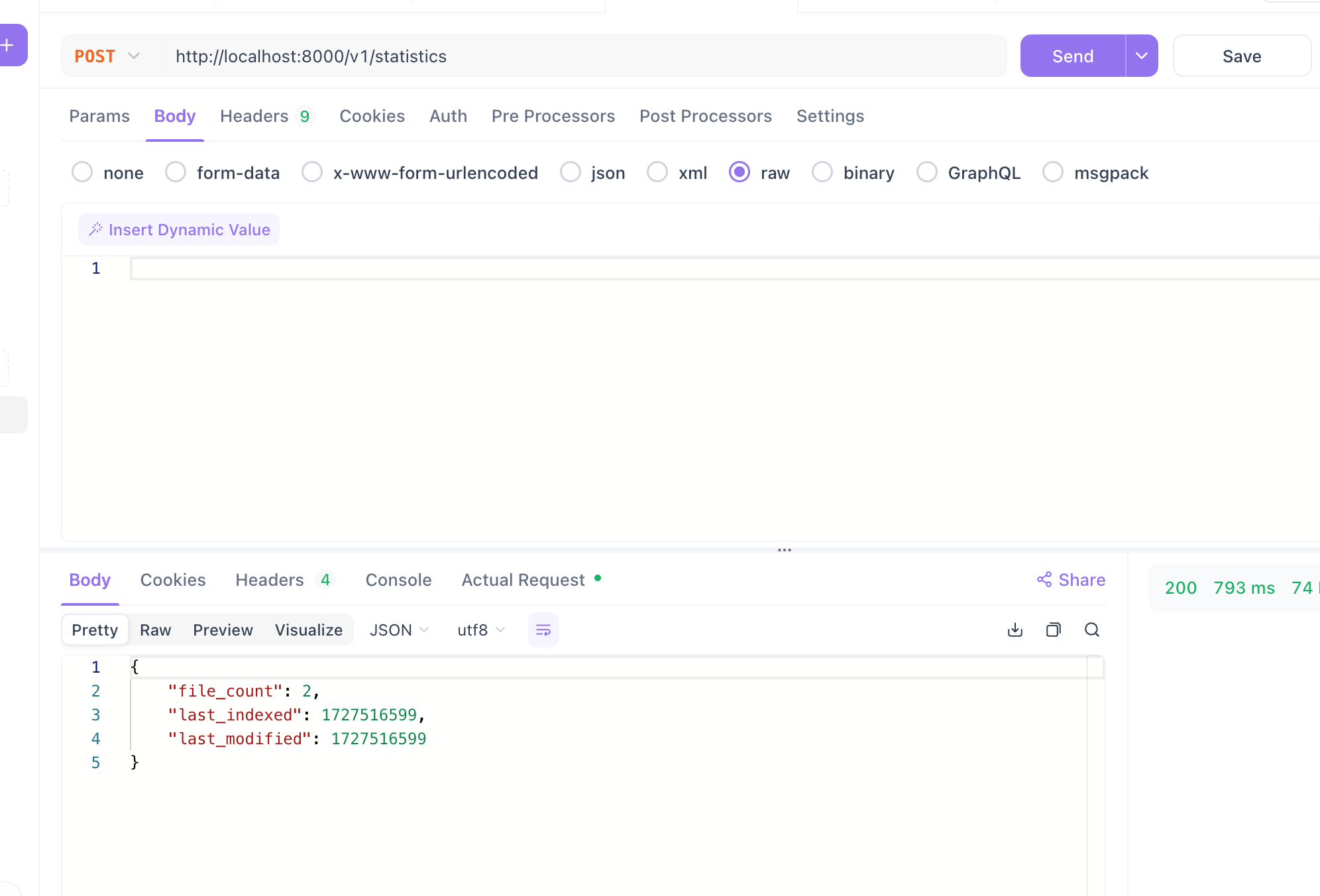
Great.
Test 3: Deleting Content
Now, delete the file created above and run the stats command again. The stats show only one file, which is correct.
Any questions related to the deleted document will also fail. For brevity, I will leave this out.
This tool solves a common business problem with data that is constantly being updated and provides intelligent RAG for heavily updated data.
Conclusion
In this post, we tested the system’s ability to dynamically update its embeddings by querying current content, adding new documents, and deleting existing ones. This setup shows Pathway’s capability to handle frequently updated document data efficiently.
There are dozens of other settings you can try, such as external sources, different models, chunking strategies, and more. Just check the documentation.