Generate Diverse Synthetic Data for LLMs with Topic Trees
When fine-tuning large language models (LLMs), the quality and diversity of your training data are crucial. However, a common pitfall is generating repetitive examples; calling an LLM with similar prompts multiple times often yields very similar results, which does not lead to robust model improvements. To build truly capable and versatile models, your training data must be highly varied.
This is where a structured approach to synthetic dataset generation becomes invaluable. One powerful and increasingly common method is the use of topic trees. This technique systematically creates different contextual prompts, leading to significantly more diverse and useful outputs for fine-tuning.
---
Why This Matters: Key Applications of Topic Tree Generation
Before we dive into the how, let's look at the impact this methodology can have on your LLM projects:
- Accelerate Model Fine-Tuning: Generate a wealth of varied training examples for supervised fine-tuning, dramatically improving your model's understanding and generalization within specific domains.
- Build Niche-Specific Datasets: Systematically explore and generate data for highly specialized domains (e.g., legal tech, medical diagnostics, obscure historical periods) where public datasets are scarce.
- Enhance Few-Shot Learning Examples: Create comprehensive and diverse sets of examples for few-shot prompting, allowing your models to quickly adapt to new tasks with minimal direct training.
- Rigorously Evaluate Models: Develop nuanced and varied test cases that cover different subtopics and contexts within a domain, providing a more thorough assessment of your model's performance.
The Topic Tree Methodology
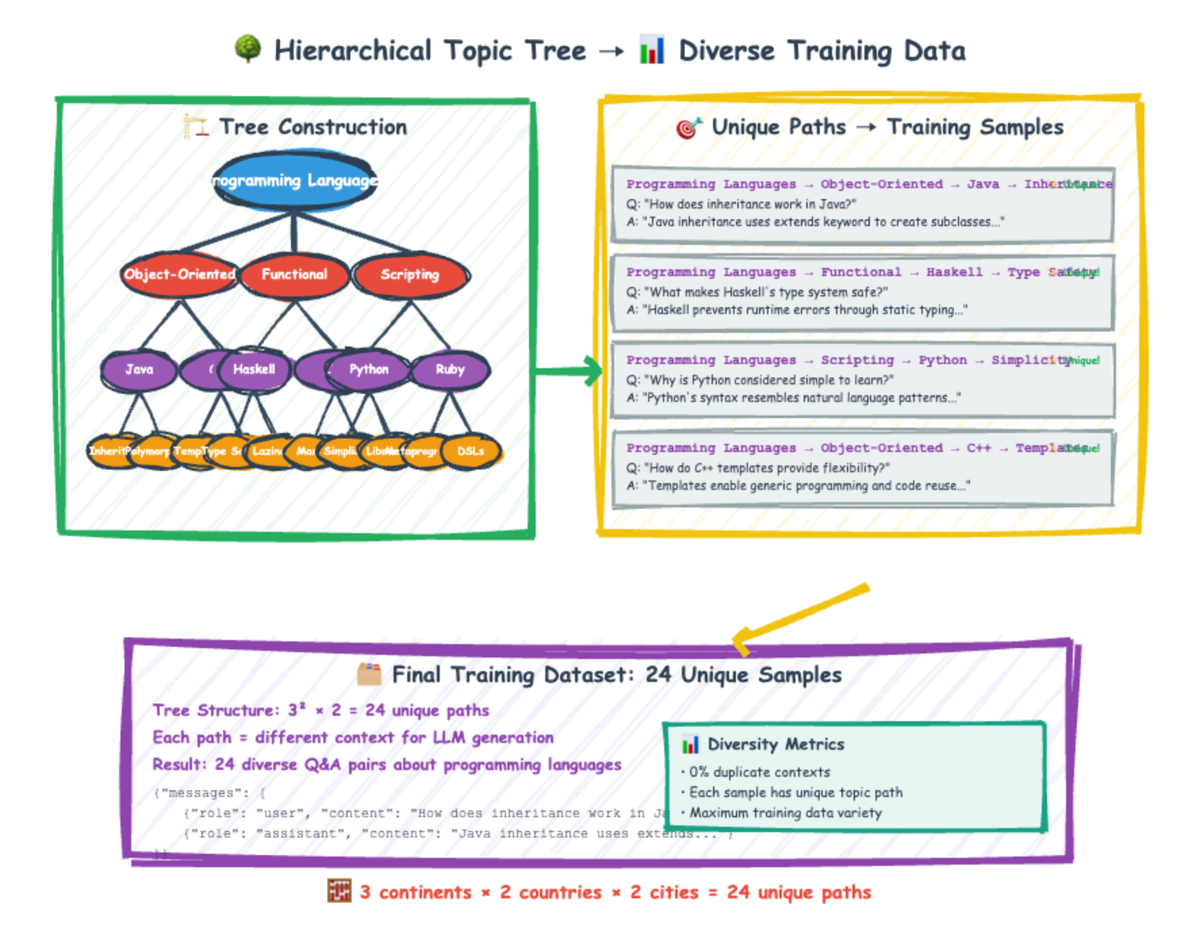
At its core, a topic tree is a hierarchical structure that systematically breaks down a broad subject into increasingly specific subtopics. Imagine a mind map, but one that is programmatically generated and used to guide data creation.
How the Approach Works (Conceptually)
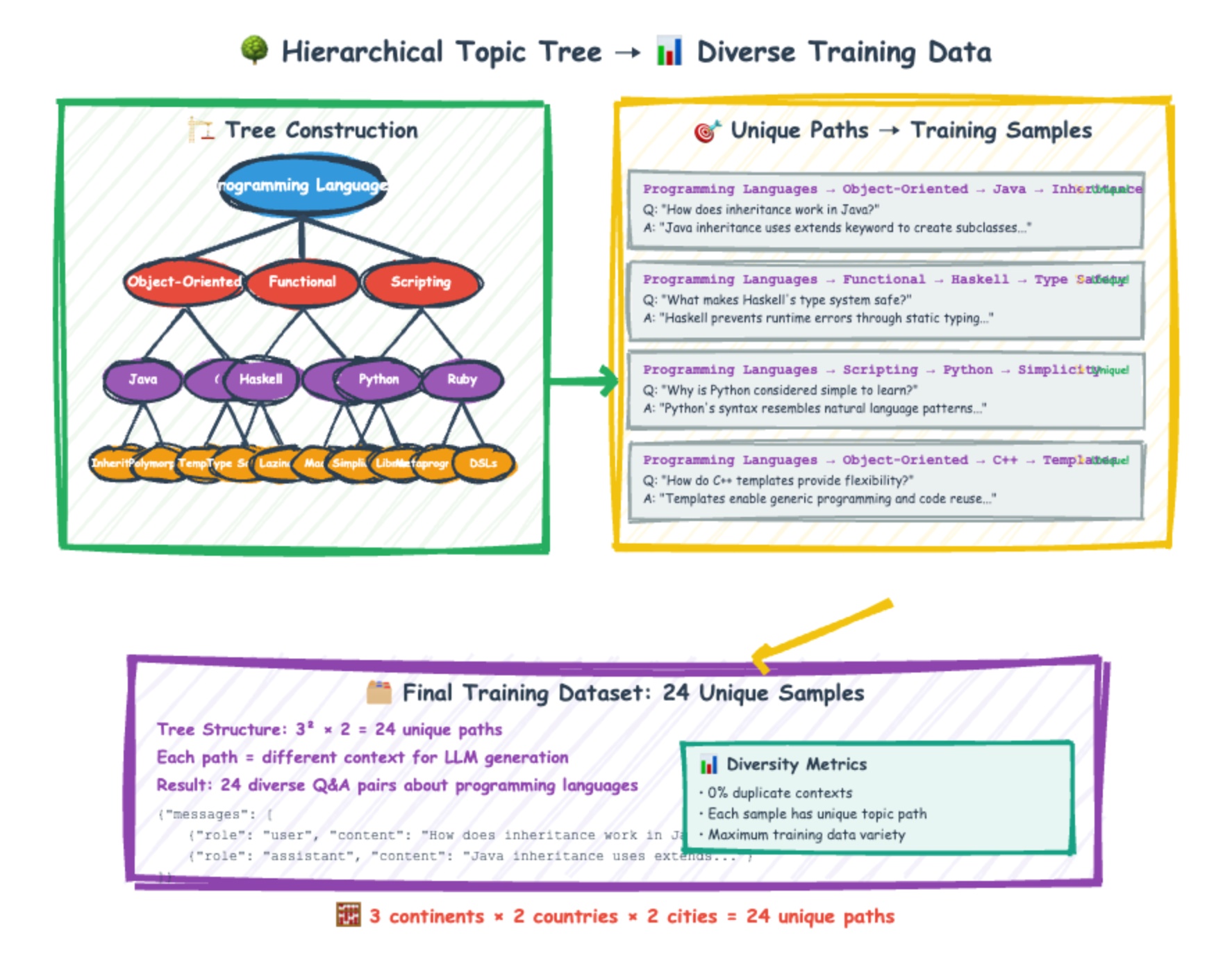
- Define a Root Topic: You start with a very broad subject or theme (e.g., "Historical Events," "Programming Concepts," "Culinary Dishes"). This is the root of your tree.
- Hierarchical Expansion: An LLM is then used to progressively generate subtopics for each node in the tree.
– For "Historical Events," the first level might be "Ancient History," "Medieval History," "Modern History."– Beneath "Ancient History," you might get "Roman Empire," "Ancient Egypt," "Greek Civilization," and so on.– This continues down to a specified depth, creating very granular contexts at the leaf nodes. - Contextual Path Generation: Once the tree is complete, every unique path from the root down to a leaf node becomes a rich, distinct context. For example:
–["Historical Events", "Ancient History", "Roman Empire", "Julius Caesar's Campaigns"]–["Historical Events", "Modern History", "World War II", "The Battle of Stalingrad"]Each path represents a unique set of contextual information, ensuring that data generated using these paths will be inherently diverse. - Data Generation: An LLM is then prompted with these unique paths (or the full context they represent) to generate specific training examples (e.g., questions, answers, summaries, code snippets) relevant to that precise context. Because each path is unique, the generated data samples will also be highly varied, avoiding the repetitive outputs of single-prompt generation.