Beyond “Hello World” - AI Coding Day2 Challenges
AI Code assistants are reshaping software development, but as projects evolve, they face the challenge of retaining memory from prior sessions. This post discusses innovative strategies like Continuous Generated Documentation to efficiently manage context loss in Large Language Models (LLMs). By ...

If you're familiar with AI Code assistants like Cursor, Copilot, or Clinet, you know how powerful they are and how they are revolutionizing the software industry. But if you've gone beyond the basic "Hello World" stage, you probably also know these tools present a lot of challenges in terms of quality, security, and more.
In this blog post, I want to discuss one of the major challenges in the later stages—beyond "Hello World": remembering the code.
When integrating Large Language Models (LLMs) into software development workflows, the real problem is that these models don’t retain memory of previous sessions. Unlike a human developer who inherently remembers the codebase structure, patterns, and design decisions from the day before, each new LLM session starts with no context.
Unless you either feed the entire codebase again or rely on techniques like Retrieval Augmented Generation (RAG), the LLM won’t know what it learned previously. This makes subsequent adjustments expensive and time-consuming.
The Core Challenge
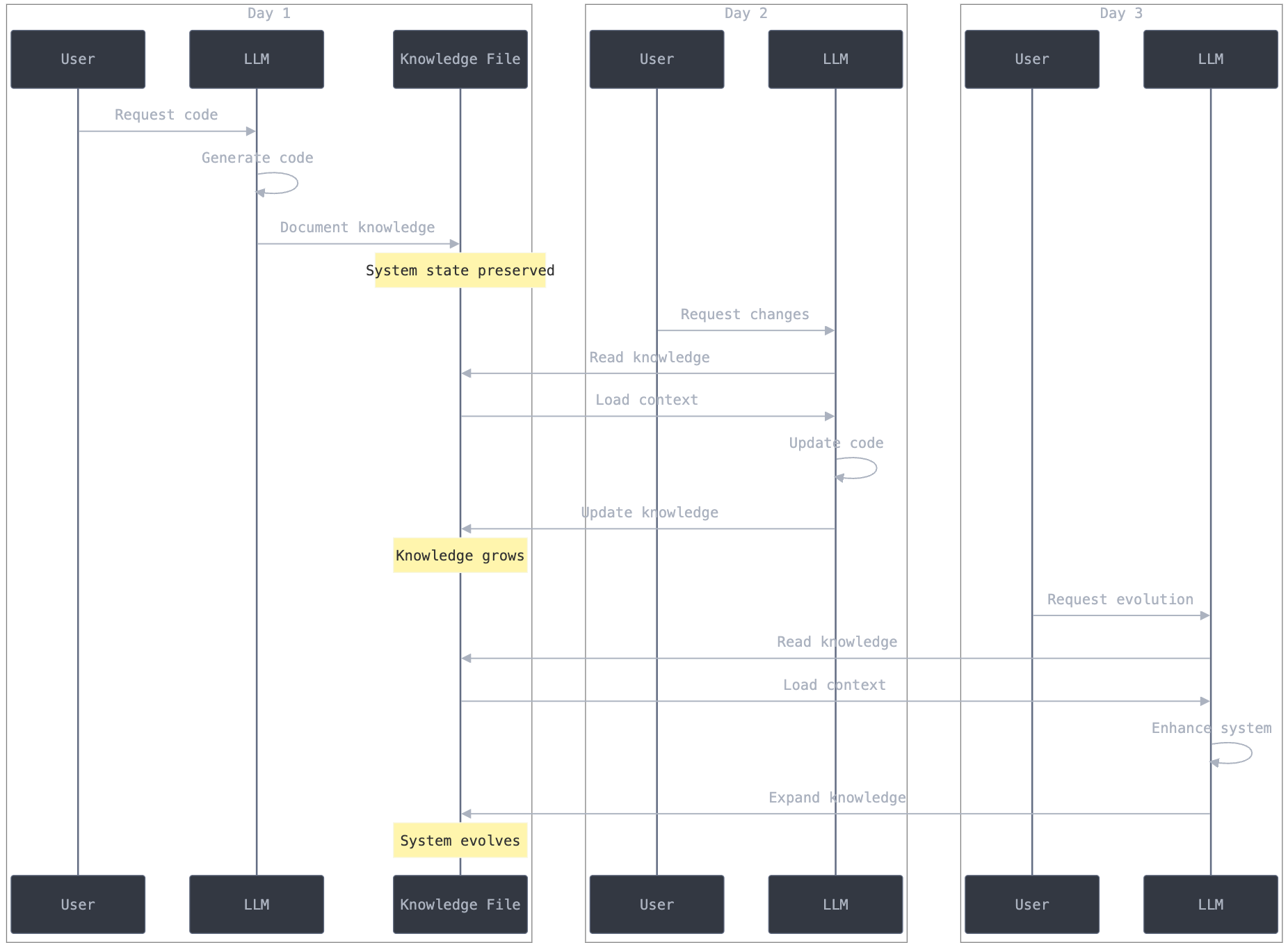
On "Day One," you might invest time and money providing the LLM with full context—every important file, architectural diagram, and established pattern. It can then generate code in alignment with your system’s design.
But on "Day Two," if you want to make a small change, you need to reintroduce all of this information. Doing so again can be costly, both in terms of context length and compute time.
Without a strategy to efficiently re-summarize or selectively feed the LLM key information, you’ll pay over and over to restore the same context. Techniques like RAG can help by pulling only relevant documents, but then you must ensure these documents are well-maintained, coherent, and accurately reflect the evolving state of the codebase.
Solution: Continuous Generated Documentation
The Idea:
If a developer (human or LLM) joins the project, you provide them with documentation: architecture diagrams, design decisions, patterns, and references. Over time, they remember these details. For LLMs, you must recreate this effect artificially through careful documentation and data retrieval strategies.
To avoid refeeding the entire repository, maintain a “digest” or condensed version of the codebase’s knowledge. This digest includes critical architecture notes, design patterns, key workflows, and any domain-specific logic. By curating such materials, you can quickly bring an LLM up to speed—even mid-project—without full context resets.
The Three-Layer Documentation Approach
Asking the LLM to create extensive documentation can save a lot of time and reduces the chance of missing important details.
Here is a sample prompt for generating comprehensive documentation (I use Claude Sonnet 3.5).
Make a documentation of everything you need to know so that someone who does not know this repo is up to date and not missing anything important when I ask them to make changes to the code.
And of course, for "day 3" you can use the same approach. You can ask the LLM to update the documentation as you change the architecture or make key changes in your code repo. It’s not about documenting everything (you still need to code); it’s about providing an overview to quickly grasp the core structure of your repo. For the rest, the LLM can navigate.
1. Development Guide (DEVELOPMENT.md)
- Purpose: A high-level textbook explaining the system architecture, patterns, and reasoning behind decisions.
- Content:
- System overview (e.g., microservices, event-driven patterns)
- Core components and their relationships
- State machines and data flow diagrams
- Configuration notes
2. Quick Reference (QUICK_REFERENCE.md)
- Purpose: A short “cookbook” with common patterns and best practices.
- Content:
- Common error handling approach (pseudo code):try {
// do work
} catch (e) {
// publish error event
// revert if needed
}
- Standard event publishing order (pseudo instructions)
- Valid state transitions (a small map of allowed state changes)
3. API Reference (API_REFERENCE.md)
- Purpose: A specification-like document with interface definitions.
- Content:
- Endpoints, request/response schemas (mostly pseudo structures)
```
POST /api/orders
Request: { items: [...], customerId: ... }
Response: { orderId: ..., status: ..., events: [...] }
```
- Common error structures (pseudo objects)
{ code: "ERR_X", message: "Something went wrong", retryable: false }
By providing these documents, you can rehydrate the LLM’s understanding more quickly. Instead of feeding it every file again, you give it this distilled knowledge, plus targeted snippets from the repo as needed.
Real-World Impact
Scenario: Adding Payment Retry Logic
- Without guidance, the LLM might just wrap calls in a simplistic retry loop.
- With documented patterns, it uses proper transactions, respects event publishing order, and aligns with known state transitions.
Scenario: Adding a New Order Status
- Without documentation, LLM adds it arbitrarily.
- With documentation, it updates state machines, event flows, and related code consistently.
Best Practices
- Keep the Digest Updated:
As the codebase evolves, update these reference docs. - Show Relationships, Not Just Facts:
Convey how components interact, not just their existence. - Align on Error Handling and Events:
Establish standard patterns once and document them for consistent reuse. - Use RAG Wisely:
Combine your documentation with a retrieval system that surfaces relevant parts as needed, balancing cost and context window usage.
Conclusion
The challenge with LLM integration isn’t that they need a rigid structure. It’s that they don’t remember previous sessions. Humans keep context in their minds, but LLMs need you to supply it every time. By maintaining a well-structured digest of your codebase’s essential knowledge—via development guides, quick references, and API specs—you can quickly bring an LLM back up to speed and ensure consistency across days and sessions.
This investment pays off by reducing reintroduction costs, ensuring coherent changes, and allowing both human and LLM contributors to stay aligned with the evolving codebase.



