Are Huge Context Windows the new RAG?
Gemini's AI now processes up to 2 million tokens, revolutionizing how massive documents like research papers, legal texts, and codebases are handled. This leap eliminates past constraints, enabling seamless analysis without dividing text. Users can simply input data, pose queries, and uncover pat...

Recently, Gemini just hit the 2 million token mark and many people are asking me what this means and how it can help them achieve more with AI.
This advancement not only allows users to add a few more pages to our chat with AI, it opens up a whole new world of possibilities that we could never have imagined a few years ago.
And I'm not just talking about asking a chatbot a simple question about a single document. I mean processing much bigger things – like research papers, entire technical documentations, codebases, legal documents, entire rulebooks, or even constitutions.
Think about it: today's advanced AI models can handle up to 1-2 million pieces of text (called tokens) in one go, often costing less than 50 cents. That's a huge step forward!
Here's a picture showing what those tokens actually represent:
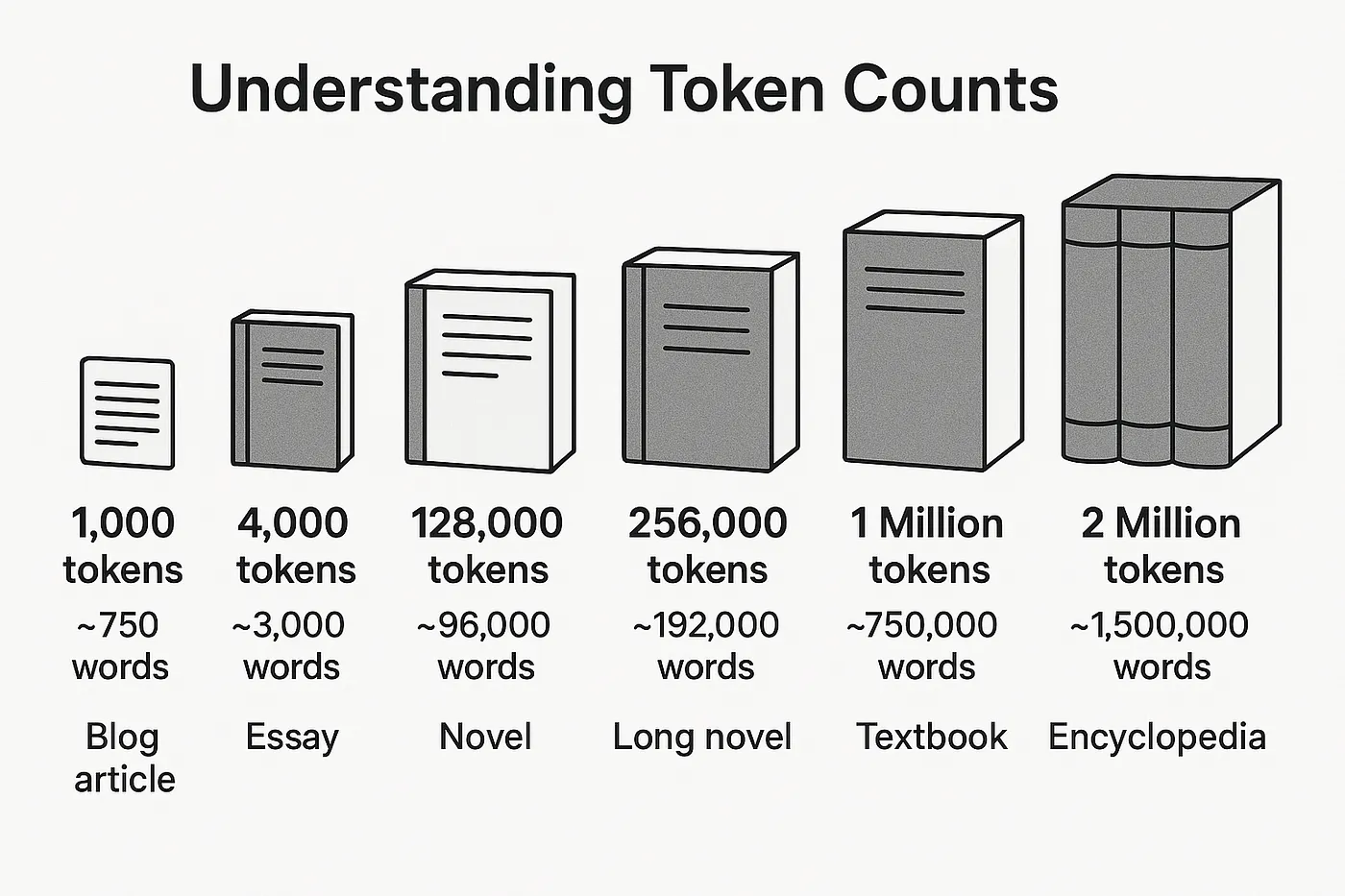
How AI Used to Handle Large Amounts of Data
Not long ago, maybe less than three years back, the "context window" – the amount of text an AI could consider at once – was tiny, maybe around 4,000 tokens. That's roughly the length of one large or a few blog posts.
Yet, you might have noticed that many chatbots could still process large documents, like PDFs, when you uploaded them.
The RAG-Approach
Basically, they didn't really read the entire PDF or whatever you uploaded all at once. Instead, they would break the document into smaller pieces. These pieces were then stored in a special kind of database (often called a "vector store"). When you asked a question, the system would search this database to find the most relevant pieces and only process those specific sections to give you an answer. This method was (and still is) efficient, but it required careful setup to make sure the AI found all the important information and didn't miss anything relevant but perhaps less obvious.
The Power of Large Context Windows
With today's large context windows, and the fact that they've become so affordable, that previous limitation is pretty much gone.
Now, the AI can process a massive amount of text without needing to break it into chunks or use that database method. You just need to give it the right content and ask your question in a clear, smart way.
Here's what the new approach offers:
- NO breaking text into chunks
- NO creating a special database
- NO complex searching for relevant pieces beforehand
- The ability to find patterns, contradictions, and connections between different parts of the text. This is one of the most significant game-changing possibilities with large context windows.
So, the process is now much simpler:
- Gather the text data you want to analyze.
- Give it to the AI model.
- Ask it questions about finding patterns, contradictions, focusing on specific points, and so on.
It's worth noting that how quickly you get a response will depend a lot on how much text (how long the context window) you are processing. So, expect it to take a bit longer to process a million tokens (like a whole lawbook) compared to, say, 10,000 tokens (like a blog post).
Preparing Your Data
The actual format of the data doesn't really matter too much. You can copy and paste text from a website, a PDF, or pretty much any source, as long as it's text (though large context models can handle images too, but that's a different topic).
Even though the format isn't critical, it's a good idea to clean up the text by removing unnecessary things like extra empty lines or spaces.
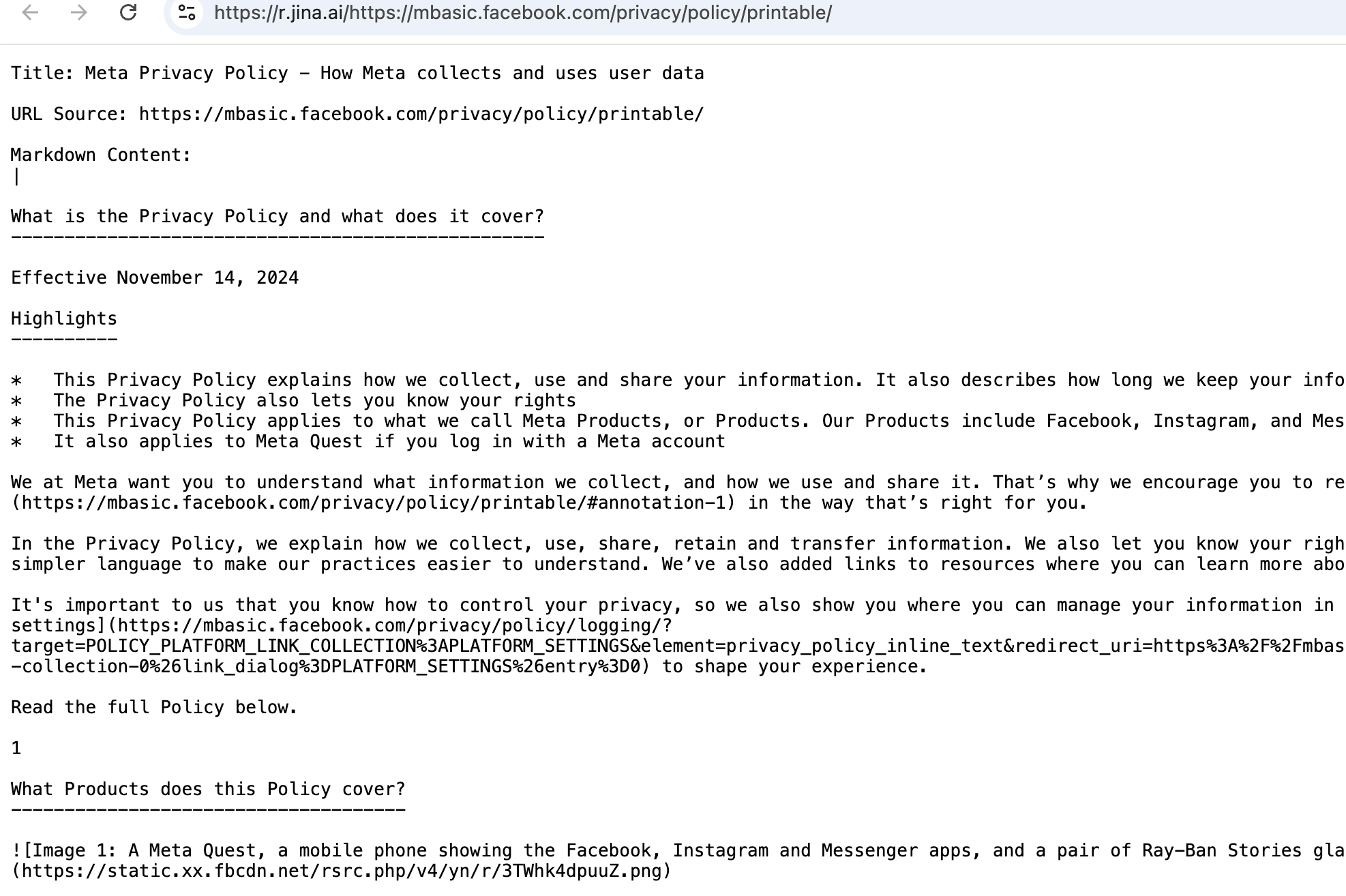
One really easy way to do this, especially for websites, is to convert the webpage into a cleaner format called Markdown using a service like r.jina.ai.
All you have to do is add the website's URL to the end of r.jina.ai/ and it will return the Markdown version of that website's content.
https://r.jina.ai/https://mbasic.facebook.com/privacy/policy/printable/
Developers could do the same for an entire codebase using tools like Repomix, which converts the codebase into a single markdown file.
Finding Your Data Sources
You could download a PDF, get text from a website using a tool (like Apify or r.jina.ai), or combine several documents you already have.
Here are some examples of where you might find data:
- Searching online for
constitution germany filetype:pdf - Looking up
Terms and conditions xyzfor a specific company, then getting the page content using a tool like Apify or r.jina.ai. - Putting together text from multiple documents you have.
And many more possibilities exist.



