100 Trillion Tokens: What the Largest AI Usage Study Reveals About How We Actually Use LLMs
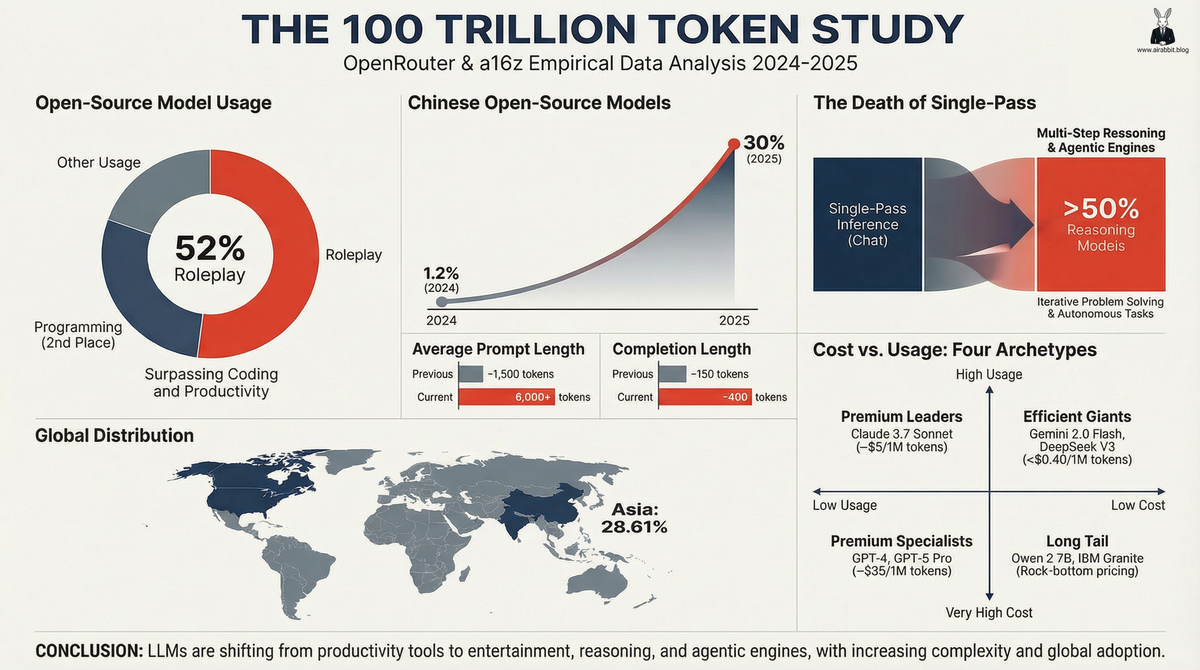
OpenRouter just published the most comprehensive empirical study on LLM usage ever conducted. The findings challenge some common assumptions about what people actually do with AI.

In this blog post, we will explore the findings, limitations and key takeaways of this study, with a particular focus on how they may be relevant to developers and businesses.
Let’s dive in!
What is OpenRouter?
OpenRouter is an API aggregator. It provides developers with a unified interface to access hundreds of different language models from various providers (OpenAI, Anthropic, Google, open-source models like Llama, DeepSeek, Qwen, and many others).
Why is this study different from previous studies (ChatGPT, Anthropic & Co.)?
You may recall similar studies from ChatGPT and Anthropic in the past. While their findings were eye-opening, this study is different because it uses solely API-based AI, which is technically different from ChatGPT and Claude app usage.
Why? When you chat with ChatGPT on your phone, you’re a consumer using a polished interface. OpenRouter users are typically developers, companies, and power users building applications, running automated pipelines, or integrating LLMs into their workflows via API calls.
So this study doesn't represent all AI usage. It represents how the developer and API ecosystem uses LLMs — which is arguably just as interesting, if not more so, for understanding where the industry is heading.
With that context, here's what 100 trillion tokens of real-world usage revealed.